
Datadog Alternative: When to Move Out?

Thanks for all help with setup, tests, and calculations Tushar & Swapnil on this one.
Introduction
As an engineer dabbling with technologies and building solutions for customers, I like Datadog. It’s one of the fastest ways to get observability setup. To add to it, their documentation and help articles are comprehensive and easy to follow making the user experience even better.
As a decision-maker, I like Datadog because I can set up observability at a relatively lower cost without having to operate and maintain my own observability system.
But there are cases where the TCO (total cost of ownership) of Datadog may not be efficient as the organization scales. We noticed this trend when speaking to our customers. Many customers after reaching a certain scale were feeling the pinch of the cost. They were looking for alternatives with hope of reducing the TCO. This led us to investigate & simulate the migration so we can prove the hypothesis and help our customers decide whether they should stay with Datadog or migrate to an alternative solution. Also, we had set up observability systems for customers based on OSS technologies, so we were already aware of the cost of setting up & operating such platforms!
Scale & Economics
While Datadog is excellent, after a certain scale one runs into challenges of the economics of a SaaS provider. You may have seen the (un)famous 65M$ bill that CoinBase pays to Datadog or a blog post by DHH about moving out of the cloud to save 7M$ annually. And lastly the post by folks at SigNoz - demonstrating the value you can derive by moving out of Datadog or many people commenting on the high prices of Datadog on the hacker news thread. There might be some hyperbole to some of these posts, and you may not be that multi B$ company which is spending tens of millions of dollars on observability bills.
At what point should an organization start looking for alternatives to SaaS providers from an economics perspective?
So, why move?
Once the company has grown beyond a certain scale, we have noticed that Datadog may or may not be the most economical choice. Especially in these times where the focus is on reducing TCO & managing/reducing cost is on everyone’s agenda, if you have a better option, then why not explore it and see if it makes sense?
Once we felt this need across few customers we work with, we did build a setup of the OSS stack and did a few things:
- We built a lab to simulate the scale to determine the cost.
- We looked at all existing Prometheus stack customers of different scales to find things like the number of time series they have, or the number of applications per host, etc. A similar exercise was done with a few Datadog customers to find out their spending and where they are spending.
- The exercise involved analyzing the infrastructure requirements, data volume, and pricing models of both platforms for different situations in which we estimated the costs for the cost-effectiveness of both platforms which enabled us to make better decisions.
Design choices & assumptions
Some assumptions for the exercise in this post
- We will only focus on this from a monitoring perspective and not compare economics in areas such as log management or APM (Application Performance Management) etc. So this comparison purely applies from a monitoring data perspective.
- Datadog Pro plan is considered for all calculations.
- For Prometheus we are considering a HA setup with Prometheus in one region (2 replicas) and Thanos (2 replicas) in another region. All costs such as EBS volumes, backup of volumes, data transfer between region & S3 costs have been considered in the calculations.
Scenarios
Inputs
In the calculator we built, one has to enter the number of hosts and custom metrics. You can also change the retention days etc.
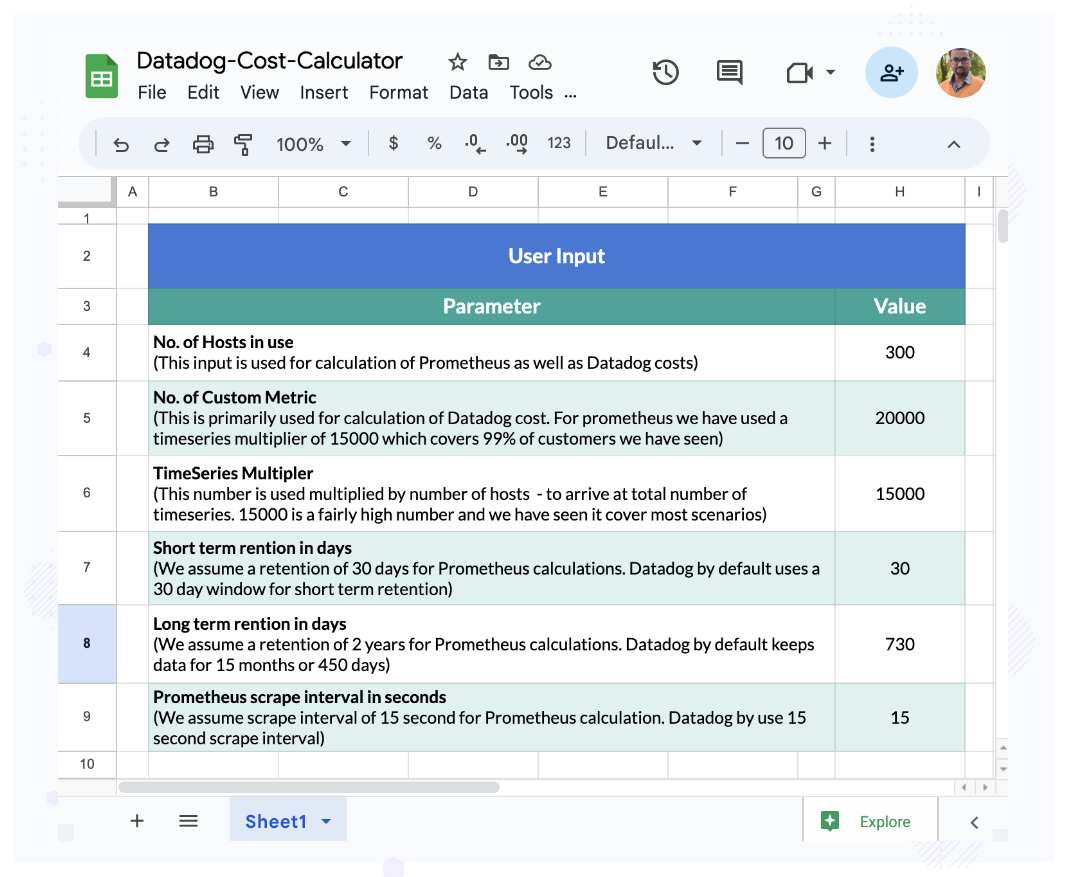
(User inputs on number of hosts and custom metrics)
Scenario 1: 300 hosts, 20K custom metrics
So let’s assume 300 hosts and 20K custom metrics as a first scenario. We will give the inputs and also find some basic compute/storage needed for Prometheus.
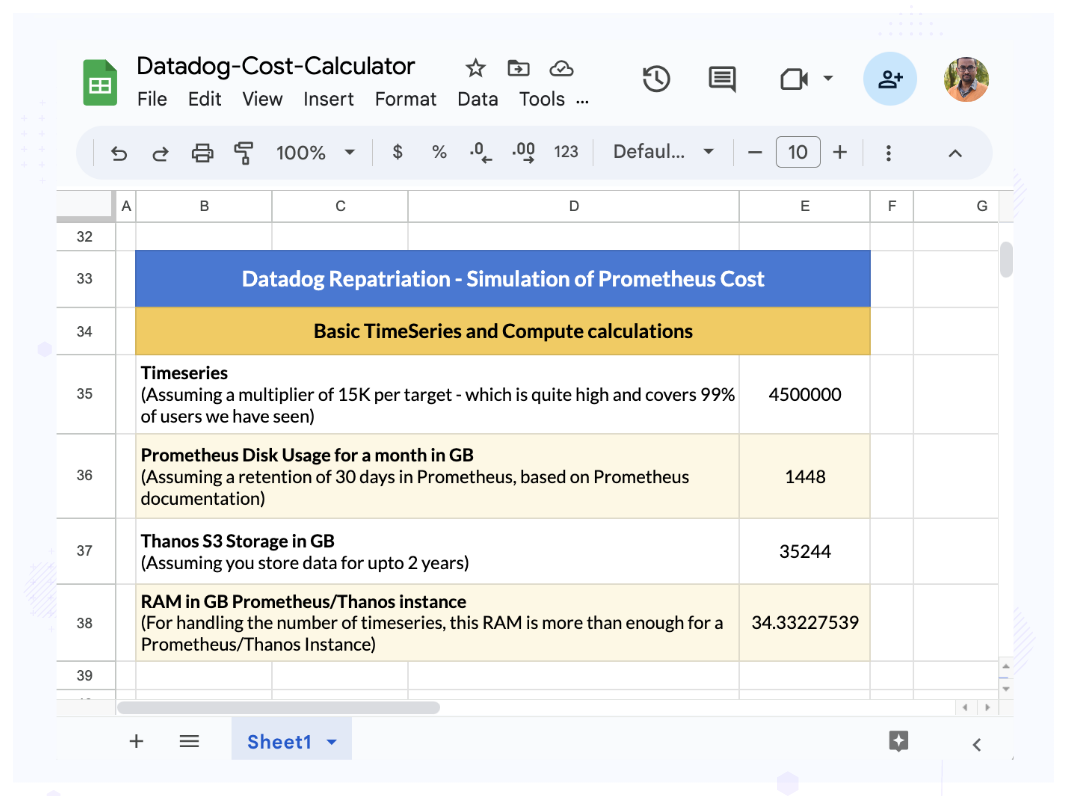
(Scenario 1 - 300 hosts and 20K custom metrics)
Now let’s get the cost of both - Prometheus and Datadog:
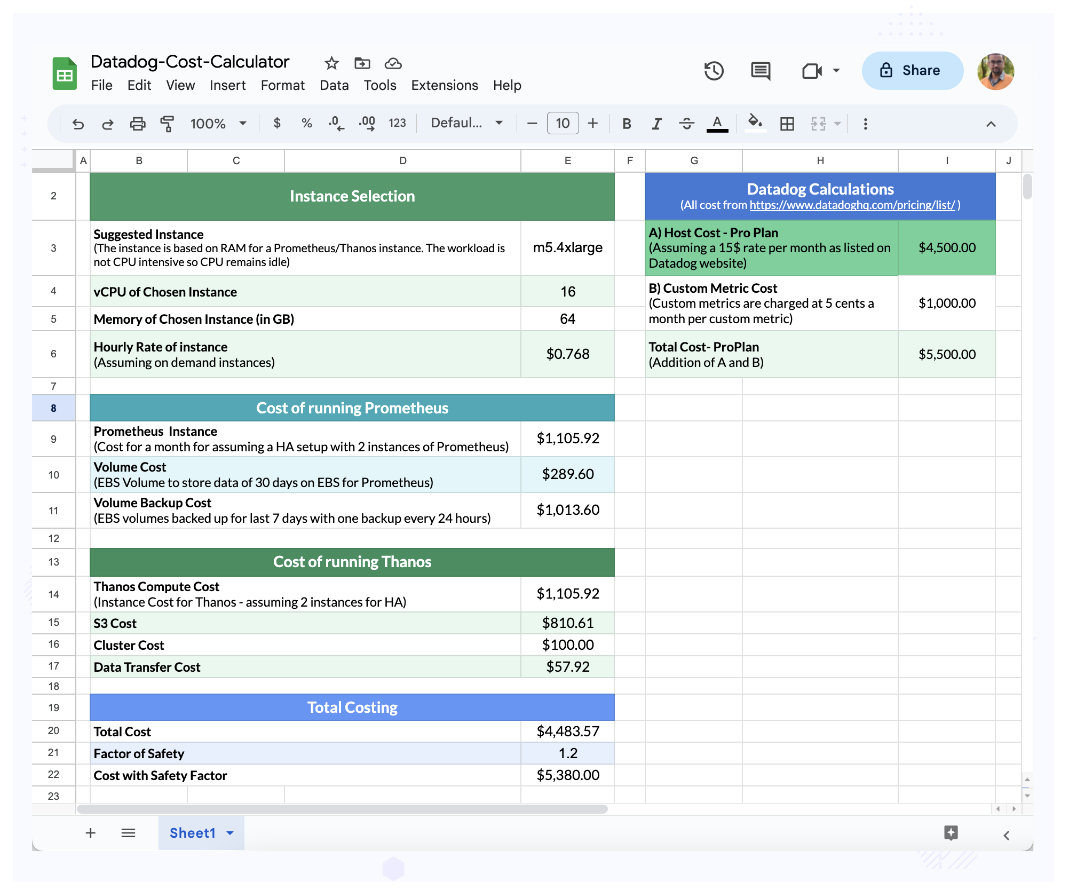
(Cost of both - Prometheus and Datadog)
So if we compare - the difference is approx ~700$ a month or 1200$ a month if you don’t consider the factor of safety addition. In either case, the cost of migration and maintenance may not justify moving out of Datadog and I would recommend the company to continue using Datadog!
Scenario 2: 300 hosts, 200K custom metrics
Now let’s bump up the number of custom metrics 10 fold to 200K which we have seen is not very uncommon for an enterprise having 300 hosts. With this the cost of Datadog shoots by 3X while the cost of Prometheus based setup remains similar.
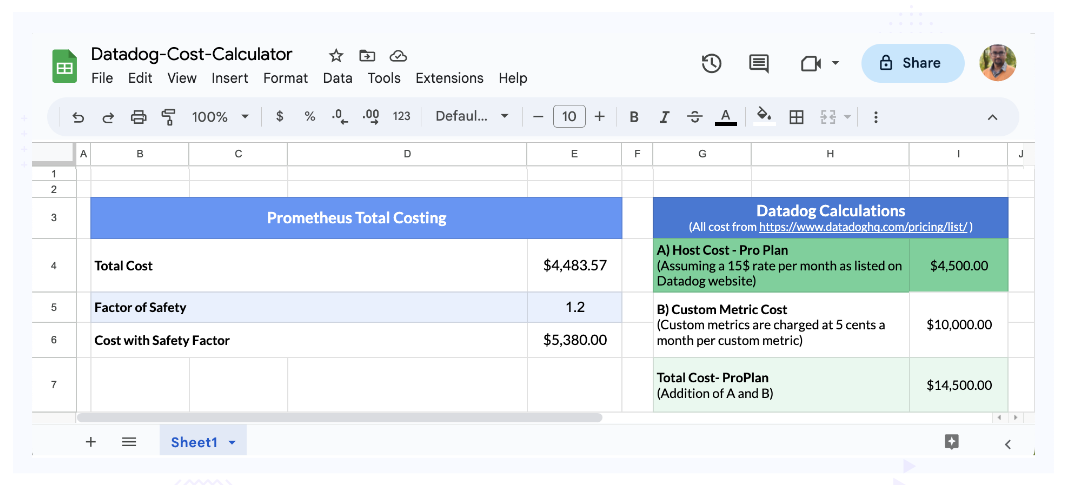
(Scenario 2: 300 hosts, 200K custom metrics)
In this case, there is definitely some value in considering moving out of Datadog and exploring Prometheus as a serious alternative. The big contribution to Datadog cost here is the custom metrics cost.
Scenario 3: 1000 hosts, 20K custom metrics
In this scenario we bump up the hosts to a fairly higher number while keeping custom metrics limited to 20K. In reality, I don’t think this is possible, with 1000 hosts, the number of custom metrics will definitely be higher, but let’s do it as an academic exercise.
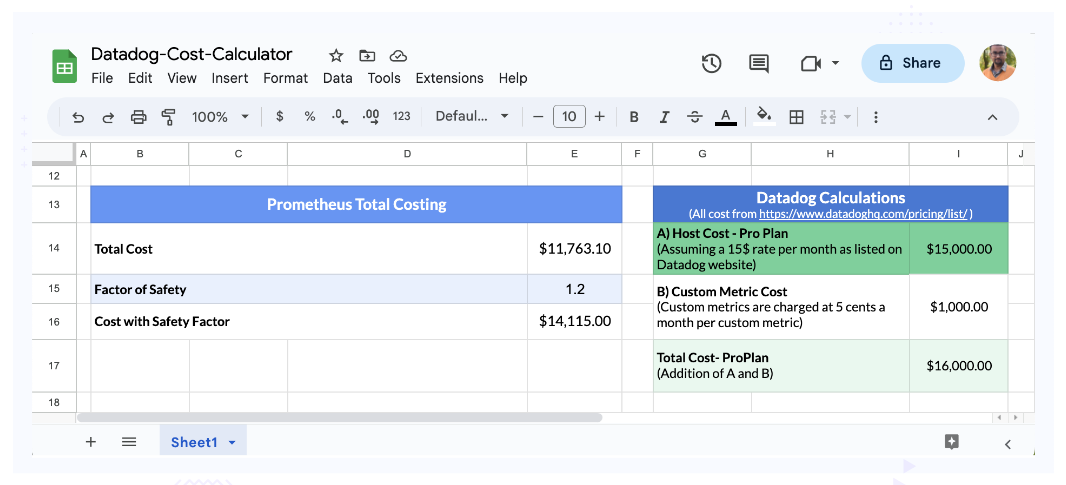
(Scenario 3: 1000 hosts, 20K custom metrics)
Similarly for this scenario, there is decent enough difference in cost and you may want to consider alternatives.
Scenario 4: 1000 hosts, 200K custom metrics
The final combination is 1000 hosts and 200K custom metrics. The actual number of custom metrics for such a large number of hosts may be in a higher range, but even with 200K custom metrics, we can see the cost of Datadog shooting up quite a bit.
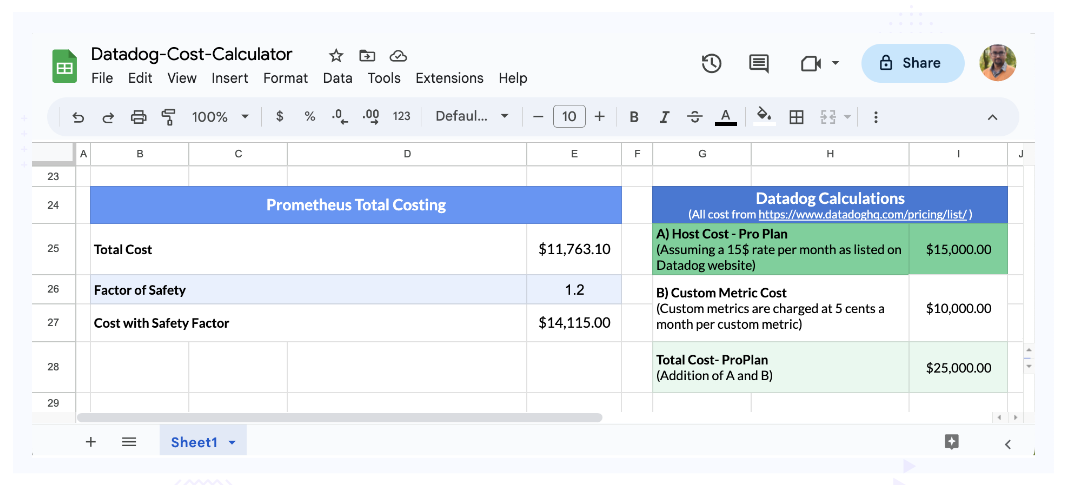
(Scenario 4: 1000 hosts, 200K custom metrics)
This is one of clear-cut scenarios and you can see that the cost difference is significant.
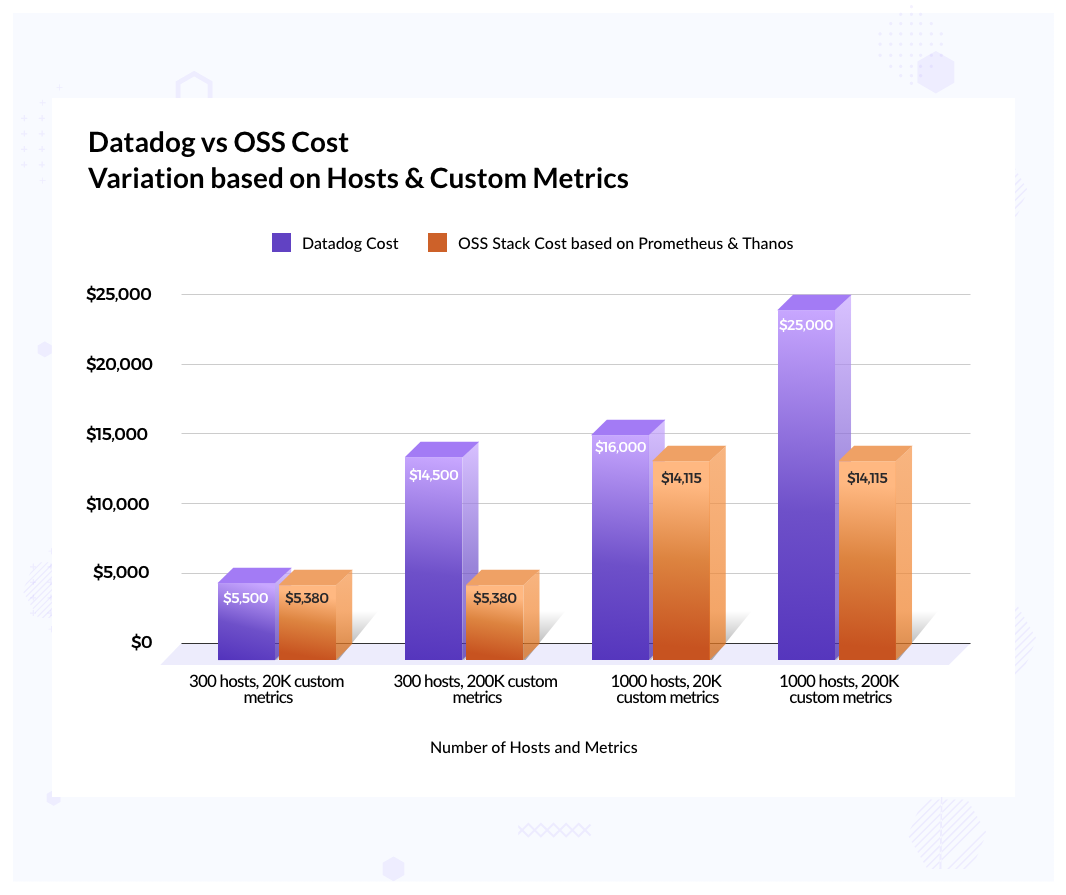
(Graph of Datadog and OSS stack cost variation based on hosts and custom metrics)
Not just visible cost!
One can not just compare the cost of a SaaS service to the infrastructure cost of running a similar stack with OSS. One has to consider the cost of migration, the cost of achieving the same experience on the OSS stack and most importantly - the cost of running/maintaining such a stack.
So basically if you consider moving to something like self-managed Prometheus beyond Datadog, there are two major contributors which would need to account for cost POV:
- The cost of migration (One time Capex)
- The cost of operating Prometheus platform without missing Datadog (Opex, recurring cost)
If the cost difference is a few thousand dollars - it may not be viable to move to Prometheus and recoup the benefits. But once you cross that threshold, it may be worth looking at the TCO and planning that migration based on the growth you are going to see in the near future.
Concluding Remarks
When the difference is more than 5-6K$ per month which translates to 60-72K$ a year, you may as well recoup the cost of migration and maintenance as well within a year. Beyond that, you are basically saving that number while not being constrained to future growth. At InfraCloud, we have helped more than 20 organizations set up and manage their observability stack. We provide Enterprise Support for Prometheus and have expertise in implementing monitoring using Thanos, Cortex and the likes. We would be happy to hear about your observations (pun intended) and experience using Datadog in your organization. If you’re exploring an alternate solution to save costs on Datadog while being effective at monitoring, we do offer consulting sessions around this. You can book a Calendly slot here.
Stay updated with latest in AI and Cloud Native tech
We hate 😖 spam as much as you do! You're in a safe company.
Only delivering solid AI & cloud native content.
Posts You Might Like










