
Primer on Distributed Parallel Processing with Ray using KubeRay

In the early days of computing, applications handled tasks sequentially. As the scale grew with millions of users, this approach became impractical. Asynchronous processing allowed handling multiple tasks concurrently, but managing threads/processes on a single machine led to resource constraints and complexity.
This is where distributed parallel processing comes in. By spreading the workload across multiple machines, each dedicated to a portion of the task, it offers a scalable and efficient solution. If you have a function to process a large batch of files, you can divide the workload across multiple machines to process files concurrently instead of handling them sequentially on one machine. Additionally, it improves performance by leveraging combined resources and provides scalability and fault tolerance. As the demands increase, you can add more machines to increase available resources.
It is challenging to build and run distributed applications on scale, but there are several frameworks and tools to help you out. In this blog post, we’ll examine one such open source distributed computing framework: Ray. We’ll also look at KubeRay, a Kubernetes operator that enables seamless Ray integration with Kubernetes clusters for distributed computing in cloud native environments. But first, let’s understand where distributed parallelism helps.
Where does distributed parallel processing help?
Any task that benefits from splitting its workload across multiple machines can utilize distributed parallel processing. This approach is particularly useful for scenarios such as web crawling, large-scale data analytics, machine learning model training, real-time stream processing, genomic data analysis, and video rendering. By distributing tasks across multiple nodes, distributed parallel processing significantly enhances performance, reduces processing time, and optimizes resource utilization, making it essential for applications that require high throughput and rapid data handling.
When distributed parallel processing is not needed?
- Small-scale applications: For small datasets or applications with minimal processing requirements, the overhead of managing a distributed system may not be justified.
- Strong data dependencies: If tasks are highly interdependent and cannot be easily parallelized, distributed processing may offer little benefit.
- Real-time constraints: Some real-time applications (e.g., Finance and ticket booking websites) require extremely low latency, which might not be achievable with the added complexity of a distributed system.
- Limited resources: If the available infrastructure cannot support the overhead of a distributed system (e.g., insufficient network bandwidth, limited number of nodes), it may be better to optimize single-machine performance.
How Ray helps with distributed parallel processing?
Ray is a Distributed Parallel Processing framework that encapsulates all the benefits of distributed computing and solutions to challenges we discussed, such as fault tolerance, scalability, context management, communication, and so on. It is a pythonic framework, allowing the use of existing libraries and systems to work with it. With Ray’s help, a programmer doesn’t need to handle the pieces of the parallel processing compute layer. Ray will take care of scheduling and autoscaling based on the specified resource requirements.
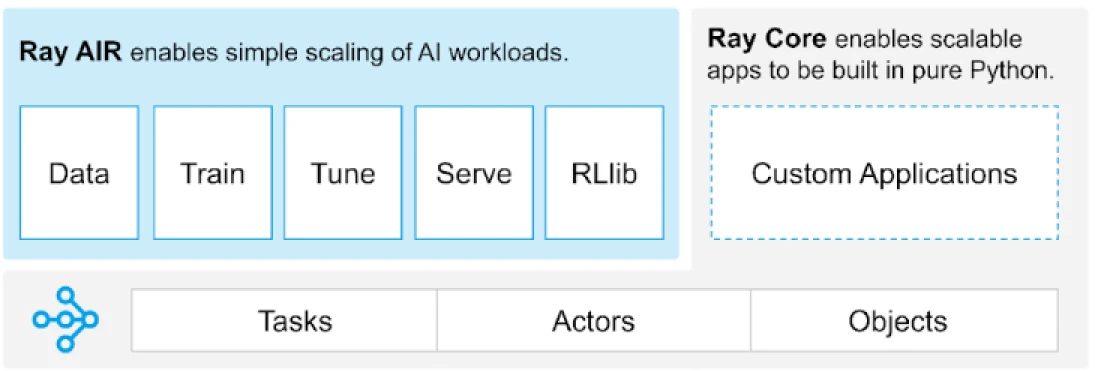
(Image Source: Ray provides a universal API of tasks, actors, and objects for building distributed applications.)
Ray provides a set of libraries built on the core primitives, i.e., Tasks, Actors, Objects, Drivers, and Jobs. These provide a versatile API to help build distributed applications. Let’s take a look at the core primitives, a.k.a. Ray Core.
Ray Core primitives
- Tasks: Ray tasks are arbitrary Python functions that are executed asynchronously on separate Python workers on a Ray cluster node. Users can specify their resource requirements in terms of CPUs, GPUs, and custom resources which are used by the cluster scheduler to distribute tasks for parallelized execution.
- Actors: What tasks are to functions, actors are to classes. An actor is a stateful worker, and the methods of an actor are scheduled on that specific worker and can access and mutate the state of that worker. Like tasks, actors support CPU, GPU, and custom resource requirements.
- Objects: In Ray, tasks and actors create and compute objects. These remote objects can be stored anywhere in a Ray cluster. Object References are used to refer to them, and they are cached in Ray’s distributed shared memory object store.
- Drivers: The program root, or the “main” program. This is the code that runs
ray.init(). - Jobs: The collection of tasks, objects, and actors originating (recursively) from the same driver and their runtime environment.
For information about primitives, you can go through the Ray Core documentation.
Ray Core key methods
Below are some of the key methods within Ray Core that are commonly used:
-
ray.init() - Start Ray runtime and connect to the Ray cluster.
import ray ray.init() -
@ray.remote - Decorator that specifies a Python function or class to be executed as a task (remote function) or actor (remote class) in a different process.
@ray.remote def remote_function(x): return x * 2 -
.remote - Postfix to the remote functions and classes; remote operations are asynchronous.
result_ref = remote_function.remote(10) -
ray.put() - Put an object in the in-memory object store; returns an object reference used to pass the object to any remote function or method call.
data = [1, 2, 3, 4, 5] data_ref = ray.put(data) -
ray.get() - Get a remote object(s) from the object store by specifying the object reference(s).
result = ray.get(result_ref) original_data = ray.get(data_ref)
An example of using most of the basic key methods:
import ray
ray.init()
@ray.remote
def calculate_square(x):
return x * x
# Using .remote to create a task
future = calculate_square.remote(5)
# Get the result
result = ray.get(future)
print(f"The square of 5 is: {result}")
How does Ray work?
Ray Cluster is like a team of computers that share the work of running a program. It consists of a head node and multiple worker nodes. The head node manages the cluster state and scheduling, while worker nodes execute tasks and manage actors.
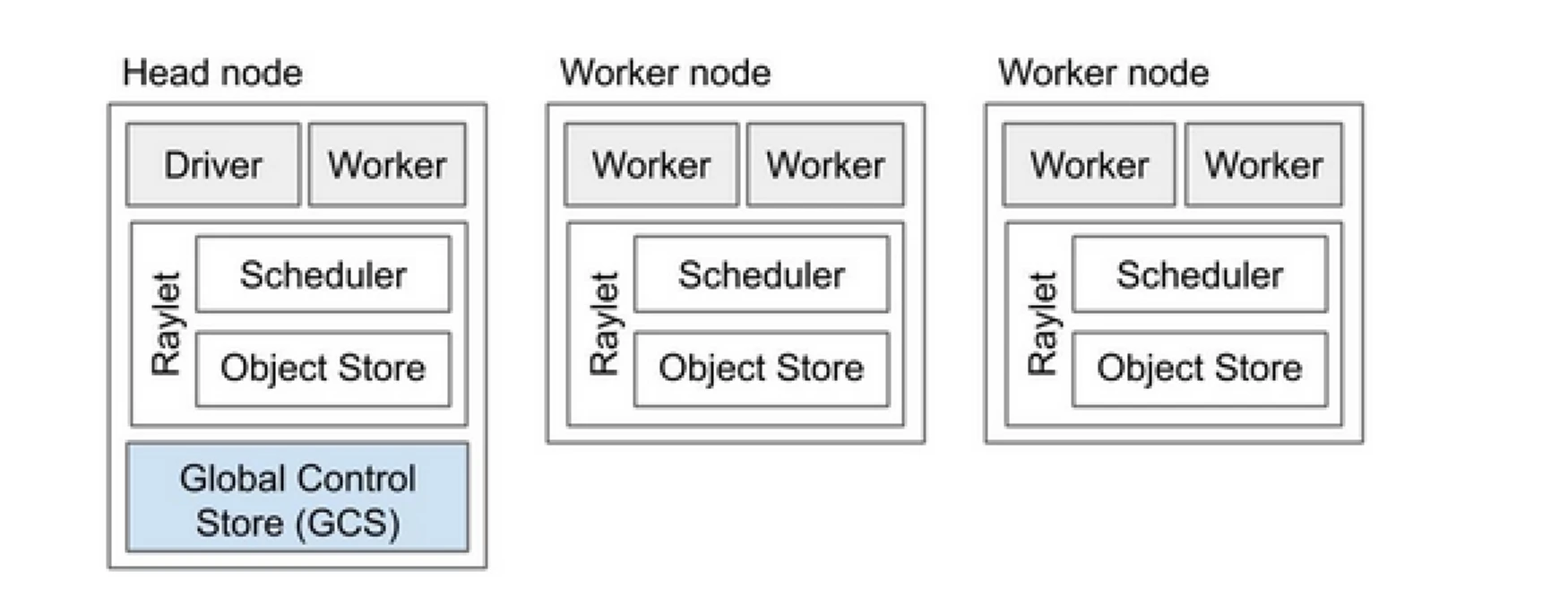
Ray Cluster components
- Global Control Store (GCS): The GCS manages the metadata and global state of the Ray cluster. It tracks tasks, actors, and resource availability, ensuring that all nodes have a consistent view of the system.
- Scheduler: The scheduler distributes tasks and actors across available nodes. It ensures efficient resource utilization and load balancing by considering resource requirements and task dependencies.
- Head node: The head node orchestrates the entire Ray cluster. It runs the GCS, handles task scheduling, and monitors the health of worker nodes.
- Worker nodes: Worker nodes execute tasks and actors. They perform the actual computations and store objects in their local memory.
- Raylet: It manages shared resources on each node and is shared among all concurrently running jobs.
You can check out the Ray v2 Architecture doc for more detailed information.
Working with existing Python applications doesn’t require a lot of changes. The changes required would mainly be around the function or class that needs to be distributed naturally. You can add a decorator and convert it into tasks or actors. Let’s see an example of this.
Converting a Python function into Ray Task
# (Normal Python function)
def square(x):
return x * x
# Usage
results = []
for i in range(4):
result = square(i)
results.append(result)
print(results)
# Output: [0, 1, 4, 9]
# (Ray Implementation)
# Define the square task.
@ray.remote
def square(x):
return x * x
# Launch four parallel square tasks.
futures = [square.remote(i) for i in range(4)]
# Retrieve results.
print(ray.get(futures))
# -> [0, 1, 4, 9]
Converting a Python Class into Ray Actor
# (Regular Python class)
class Counter:
def __init__(self):
self.i = 0
def get(self):
return self.i
def incr(self, value):
self.i += value
# Create an instance of the Counter class
c = Counter()
# Call the incr method on the instance
for _ in range(10):
c.incr(1)
# Get the final state of the counter
print(c.get()) # Output: 10
# (Ray implementation in actor)
# Define the Counter actor.
@ray.remote
class Counter:
def __init__(self):
self.i = 0
def get(self):
return self.i
def incr(self, value):
self.i += value
# Create a Counter actor.
c = Counter.remote()
# Submit calls to the actor. These
# calls run asynchronously but in
# submission order on the remote actor
# process.
for _ in range(10):
c.incr.remote(1)
# Retrieve final actor state.
print(ray.get(c.get.remote()))
# -> 10
Storing information in Ray Objects
import numpy as np
# (Regular Python function)
# Define a function that sums the values in a matrix
def sum_matrix(matrix):
return np.sum(matrix)
# Call the function with a literal argument value
print(sum_matrix(np.ones((100, 100)))) # Output: 10000.0
# Create a large array
matrix = np.ones((1000, 1000))
# Call the function with the large array
print(sum_matrix(matrix)) # Output: 1000000.0
# (Ray implementation of function)
import numpy as np
# Define a task that sums the values in a matrix.
@ray.remote
def sum_matrix(matrix):
return np.sum(matrix)
# Call the task with a literal argument value.
print(ray.get(sum_matrix.remote(np.ones((100, 100)))))
# -> 10000.0
# Put a large array into the object store.
matrix_ref = ray.put(np.ones((1000, 1000)))
# Call the task with the object reference as argument.
print(ray.get(sum_matrix.remote(matrix_ref)))
# -> 1000000.0
To learn more about its concept, head over to Ray Core Key Concept docs.
Ray vs traditional approach of distributed parallel processing
Below is a comparative analysis between the Traditional (without Ray) Approach vs Ray on Kubernetes to enable distributed parallel processing.
| Aspect | Traditional Approach | Ray on Kubernetes |
|---|---|---|
| Deployment | Manual setup and configuration | Automated with KubeRay Operator |
| Scaling | Manual scaling | Automatic scaling with RayAutoScaler and Kubernetes |
| Fault Tolerance | Custom fault tolerance mechanisms | Built-in fault tolerance with Kubernetes and Ray |
| Resource Management | Manual resource allocation | Automated resource allocation and management |
| Load Balancing | Custom load balancing solutions | Built-in load balancing with Kubernetes |
| Dependency Management | Manual dependency installation | Consistent environment with Docker containers |
| Cluster Coordination | Complex and manual | Simplified with Kubernetes service discovery and coordination |
| Development Overhead | High, with custom solutions needed | Reduced, with Ray and Kubernetes handling many aspects |
| Flexibility | Limited adaptability to changing workloads | High flexibility with dynamic scaling and resource allocation |
Kubernetes provides an ideal platform for running distributed applications like Ray due to its robust orchestration capabilities. Below are the key pointers that set the value on running Ray on Kubernetes –
- Resource management
- Scalability
- Orchestration
- Integration with ecosystem
- Easy deployment and management
KubeRay Operator to make it possible to run Ray on Kubernetes.
What is KubeRay?
The KubeRay Operator simplifies managing Ray clusters on Kubernetes by automating tasks such as deployment, scaling, and maintenance. It uses Kubernetes Custom Resource Definitions (CRDs) to manage Ray-specific resources.
KubeRay CRDs
It has three distinct CRDs.
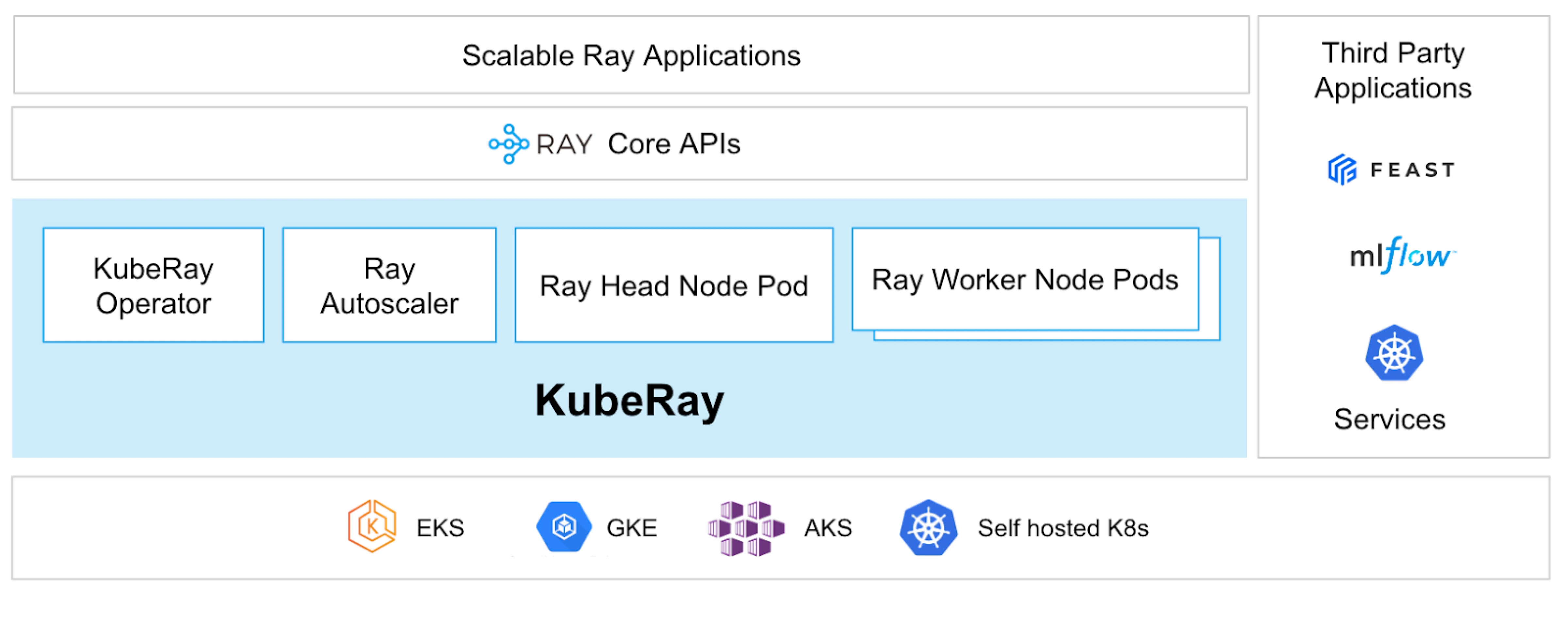
- RayCluster: This CRD helps manage RayCluster’s lifecycle and takes care of AutoScaling based on the configuration defined.
- RayJob: It is useful when there is a one-time job you want to run instead of keeping a standby RayCluster running all the time. It creates a RayCluster and submits the job when ready. Once the job is done, it deletes the RayCluster. This helps in automatically recycling the RayCluster.
- RayService: This also creates a RayCluster but deploys a RayServe application on it. This CRD makes it possible to do in-place updates to the application, providing zero-downtime upgrades and updates to ensure the high-availability of the application.
Use-cases of KubeRay
Deploying an on-demand model using RayService
RayService allows you to deploy models on-demand in a Kubernetes environment. This can be particularly useful for applications like image generation or text extraction, where models are deployed only when needed.
Here is an example of Stable Diffuison. Once it is applied in Kubernetes, it will create RayCluster and also run a RayService, which will serve the model until you delete this resource. It allows users to take control of resources.
Training a model on a GPU cluster using RayJob
RayService serves different requirements to the user, where it keeps the model or application deployed until it is deleted manually. In contrast, RayJob allows one-time jobs for use cases like training a model, preprocessing data, or inference for a fixed number of given prompts.
Run inference server on Kubernetes using RayService or RayJob
Generally, we run our application in Deployments, which maintains the rolling updates without downtime. Similarly, in KubeRay, this can be achieved using RayService, which deploys the model or application and handles the rolling updates.
However, there could be cases where you just want to do batch inference instead of running the inference servers or applications for a long time. This is where you can leverage RayJob, which is similar to the Kubernetes Job resource.
Image Classification Batch Inference with Huggingface Vision Transformer is an example of RayJob, which does Batch Inferencing.
These are the use cases of KubeRay, enabling you to do more with the Kubernetes cluster. With the help of KubeRay, you can run mixed workloads on the same Kubernetes cluster and offload GPU-based workload scheduling to Ray.
Conclusion
Distributed parallel processing offers a scalable solution for handling large-scale, resource-intensive tasks. Ray simplifies the complexities of building distributed applications, while KubeRay integrates Ray with Kubernetes for seamless deployment and scaling. This combination enhances performance, scalability, and fault tolerance, making it ideal for web crawling, data analytics, and machine learning tasks. By leveraging Ray and KubeRay, you can efficiently manage distributed computing, meeting the demands of today’s data-driven world with ease.
Not only that, but as our compute resource types are changing from CPU to GPU-based, it becomes important to have efficient and scalable cloud infrastructure for all sorts of applications, whether it be AI or large data processing. For that, you can bring in AI and GPU Cloud experts onboard to help you out.
We hope you found this post informative and engaging. For more posts like this one, subscribe to our weekly newsletter. We’d love to hear your thoughts on this post, so do start a conversation on LinkedIn :)
Stay updated with latest in AI and Cloud Native tech
We hate 😖 spam as much as you do! You're in a safe company.
Only delivering solid AI & cloud native content.
Posts You Might Like









