Guide to GPU Sharing Techniques: vGPU, MIG and Time Slicing

Optimizing GPU utilization is essential in modern computing, particularly for AI and ML processing, where GPUs play a pivotal role due to their unparalleled ability to handle parallel computations and process large datasets rapidly. Modern GPUs are invaluable in these fields. They have thousands of cores that enable very high parallelism. This enables complex model training and real-time data analysis that are impractical with traditional CPUs.
By fully utilizing GPU resources, organizations can accelerate MLOps workflows, achieve faster insights, and enhance the efficiency of their computing infrastructure. This leads to significant cost savings by reducing the need for additional hardware and operational expenses, while also improving scalability and flexibility to meet the dynamic demands of contemporary computational tasks. One key method for optimizing GPU utilization is by sharing the GPUs among different workloads. This is where virtual GPU (vGPU), Multi-Instance GPUs (MIG) and GPU Time-Slicing come to our rescue!
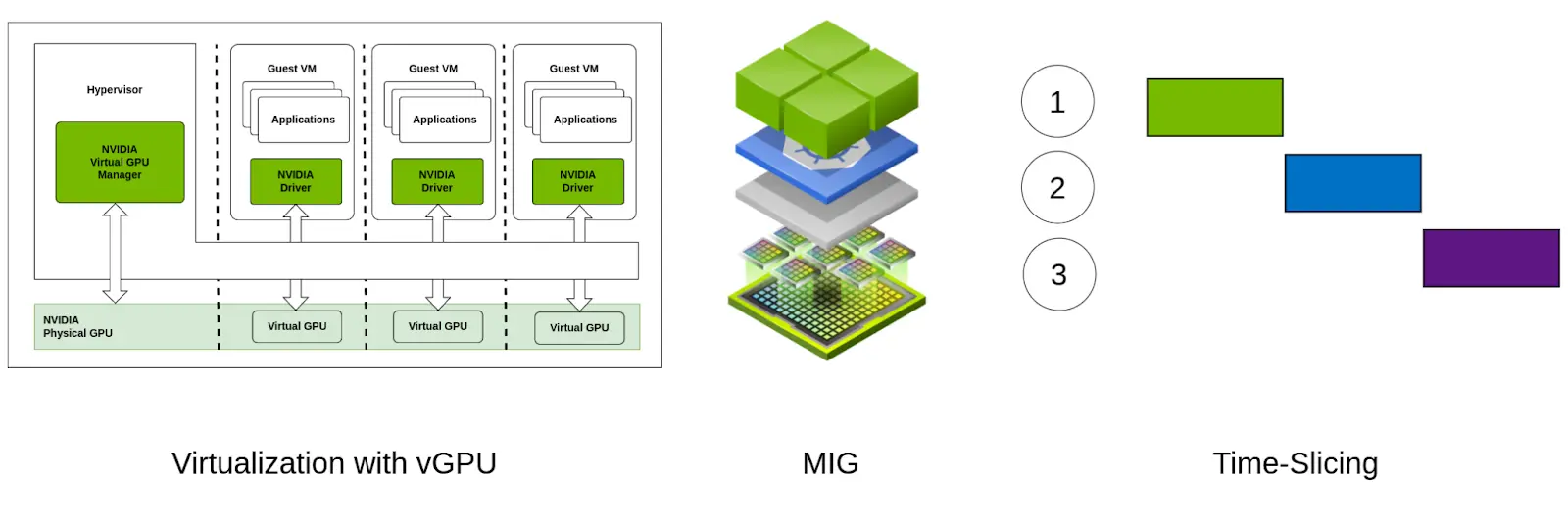
GPU optimization techniques
vGPU, MIG and GPU Time-Slicing all aim to optimize the utilization of GPU resources by enabling multiple tasks or users to share a single physical GPU. Though, there are some differences between them in terms of their working, hardware requirements & use-cases. In this blog post, we will clarify these differences and help you make the best choice for better GPU optimization.
Virtual GPU (vGPU)
vGPU, or Virtual GPU, is a technology that allows a physical GPU to be shared among multiple virtual machines (VMs). Each VM gets its own dedicated portion of the GPU’s resources, enabling multiple users or applications to access GPU acceleration simultaneously. This virtualization technology is essential for environments that require high-performance graphics or compute capabilities for consistent and predictable performance for each VM.
vGPU use cases
vGPU is useful where GPU needs to be made available on a virtual machine. Some specific examples of the same are virtual desktop infrastructure (VDI), cloud gaming, and remote workstation scenarios.
For AI/ML processing, vGPU is important to run the workloads in containerized environments.
Benefits of vGPU
- vGPU allows each VM to have its own dedicated portion of the GPU’s resources. This ensures consistent and predictable performance for each VM.
- Since resources are allocated statically, workloads running in one VM do not interfere with those in another, preventing performance degradation due to resource contention.
- Each vGPU instance operates within its own VM, providing strong security boundaries. This isolation is crucial for multi-tenant environments where data privacy and security are paramount and often mandatory in highly regulated industries.
- Errors or faults in one vGPU instance are contained within that instance, preventing them from affecting other VMs sharing the same physical GPU.
- Though the maximum number of partitions depends on the GPU instance model and the vGPU manager software, vGPU supports creating up to 20 partitions per GPU with A100 80GB GPU and NVIDIA Virtual Compute Server (vCS).
How does vGPU work?
vGPU works by creating virtual instances of the GPU hardware that can be assigned to individual VMs. The process generally involves the following parts.
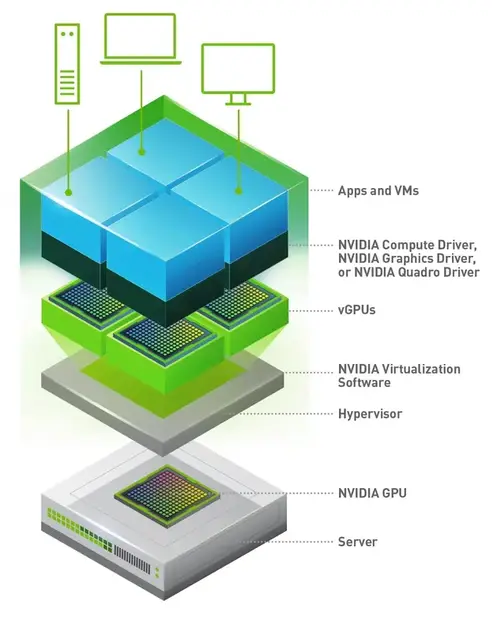
GPU virtualization
GPU virtualization is the process of abstracting the physical GPU hardware to create multiple virtual GPUs (vGPUs) that can be allocated to different virtual machines (VMs) or containers. The GPU abstraction is achieved and managed by a combination of software components, including hypervisor and specialized GPU drivers.
Hypervisor integration
A hypervisor, such as VMware vSphere, Citrix XenServer, or KVM (Kernel-based Virtual Machine), manages the allocation and scheduling of vGPUs. The hypervisor includes a GPU management layer that interfaces with the physical GPU and controls the distribution of GPU resources to VMs.
Driver and software stack
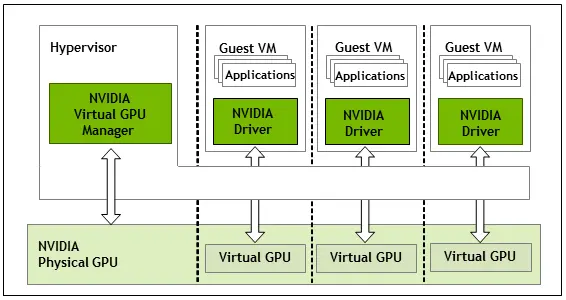
(vGPU architecture for NVIDIA vGPU)
Following are the key components involved in the enabling vGPUs on a host machine.
- Host Driver: This driver runs on the hypervisor or host operating system and manages the physical GPU, dividing its resources into virtual instances.
- Guest Driver: Installed within each VM, this driver communicates with the host driver to access the assigned vGPU resources.
- vGPU Manager: A software component provided by GPU vendors (e.g., NVIDIA) that facilitates the creation and management of vGPUs.
Note: In some cases, you may not need the Host Driver and GPU Manager together. Only one of them might be sufficient. Please refer to the manufacturer documentation for the specific guidelines.
Resource allocation
Each VM is allocated a portion of the GPU’s resources based on predefined profiles. These profiles determine how much GPU memory and compute power each VM gets, ensuring fair distribution and optimal utilization.
Hardware requirements for GPU virtualization
To enable and use vGPU, you do need a specific GPU that is compatible with virtualization although most modern GPUs are compatible with virtualization. NVIDIA offers several GPUs that support vGPU, primarily from their Tesla, Quadro, and A100 series. AMD Firepro S-Series also supports virtualization with SR-IOV.
Multi-Instance GPU (MIG)
Multi-Instance GPU (MIG) is a technology introduced by NVIDIA in May 2020. It allows a single physical GPU to be partitioned into multiple isolated GPU instances at the hardware level. Each instance operates independently, with its own dedicated compute, memory, and bandwidth resources. This enables multiple users or applications to share a single GPU while maintaining performance isolation and security.
Since MIG allows GPU partitioning at the hardware level it allows better performance with less overhead and better security.
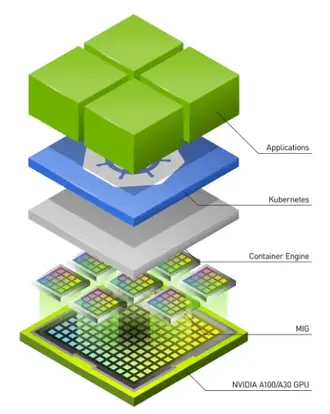
MIG use cases
Multi-Instance GPU is typically used for GPU intensive applications such as HPC workloads, hyperparameter tuning, etc. It is also used for AI model training and Inference servers where high performance and higher security between processes is required.
Benefits of MIG
- MIG ensures that GPU resources are fully utilized, reducing idle times and improving overall efficiency.
- MIG static partitioning of GPUs into multiple isolated instances, each with its own dedicated portion of resources including streaming multiprocessor (SM); ensuring better and predictable streaming multiprocessor (SM) quality of service (QoS).
- Dedicated portion of memory within multiple isolated instances ensures better memory QoS.
- Static partitioning also provides error isolation, resulting in fault containment and system stability.
- Better data protection and isolation of malicious activities, providing better security for multi-tenant setups.
How does MIG work?

NVIDIA MIG implements GPU sharing at the hardware level. The GPU chip resources such as CUDA Cores and memory are divided at the hardware level into smaller, isolated instances.
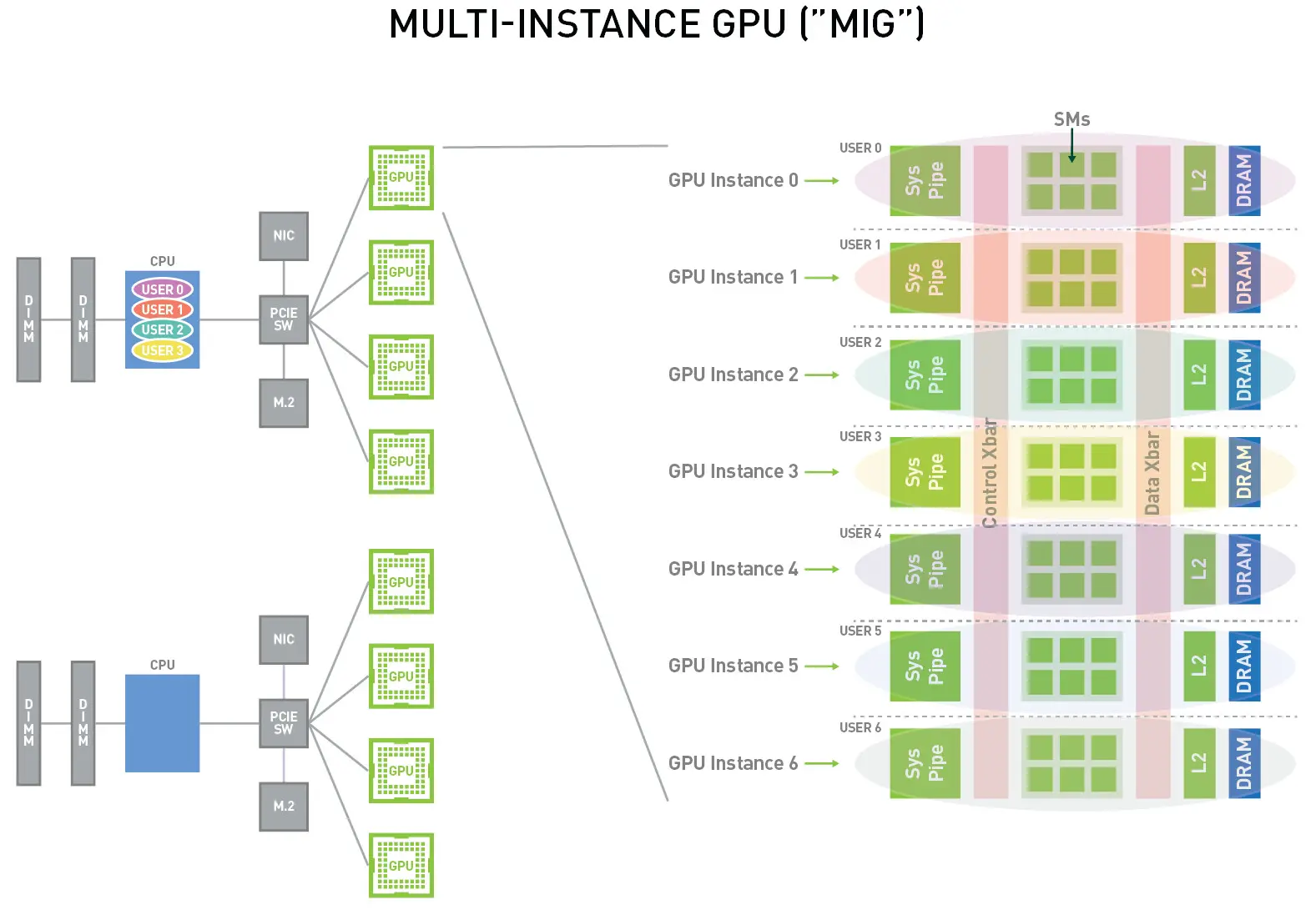
MIG technology works by a combination of multiple architectural features built into the GPU. Here are some of the important features:
- SM Partitioning: SMs (Streaming Multiprocessors) are core computational units of the GPU. The GPU architecture allows to assign a specific number of SMs to each MIG instance based on the chosen configuration.
- Memory Partitioning: The GPU’s memory is divided into channels. The architecture allows each channel to be assigned to different instances. This gives each MIG instance exclusive access to its own memory.
- High-Speed Interconnects: The internal high-speed interconnects within the GPU are partitioned to ensure that each instance has access to its fair share of bandwidth.
MIG Features
Hardware partitioning
MIG leverages the architecture of NVIDIA’s A100 GPUs, which are designed with the capability to be split into up to seven separate GPU instances. Each instance, known as an “MIG slice,” can be configured with varying amounts of GPU resources, such as memory and compute cores.
Isolation and security
Each MIG slice operates independently of the others, with hardware-enforced isolation. This ensures that the workloads running on one instance do not interfere with those on another, providing a secure and predictable performance environment. The isolation also prevents any potential security breaches or data leaks between instances.
Resource allocation
The GPU’s resources are divided into instances through a combination of firmware and software. Administrators can create and manage these instances based on the specific needs of their workloads. For example, a large training job might require a bigger slice with more memory and compute power, while smaller inference tasks could use smaller slices.
Hardware requirements
Multi-Instance GPU is a new technology that is only supported by a few GPU series models. It was launched with the NVIDIA A100 series and as of June 2024, it is currently only supported by NVIDIA Ampere, Blackwell and Hopper generation GPUs (Source). Some example models of these generations are A100, B100/200 and H100/200 GPUs respectively.
GPU Time-Slicing
GPU Time-Slicing is a virtualization technique that allows multiple workloads or virtual machines (VMs) to share a single GPU by dividing its processing time into discrete slices. Each slice allocates a portion of the GPU’s compute and memory resources to different tasks or users in a sequential manner. This enables concurrent execution of multiple tasks on a single GPU, maximizing resource utilization and ensuring fair allocation of GPU time to each workload.
GPU Time-Slicing use cases
GPU Time-Slicing is useful for all workloads where a large number of jobs need to be executed on limited hardware. It is suitable for scenarios where complex resource management is not required and for tasks that can tolerate variable GPU access and performance.
Benefits of GPU Time-Slicing
- Maximizes resource utilization and reduces idle time, without the need of specialized hardware or proprietary software.
- Reduces the need for additional hardware thus lowering operational costs.
- Provides flexibility to handle varying computational requirements based on workload demands.
- Time-Slicing is relatively simple to implement and manage, making it suitable for environments where complex resource management is not required.
- This method is effective for non-critical tasks that can tolerate variability in GPU access and performance, such as background processing or batch jobs.
- Unlimited number of max partitions available.
Limitations of GPU Time-Slicing
- Frequent context switching between different workloads can introduce performance overhead and add latency to task executions, reducing the overall efficiency of GPU utilization.
- The GPUs may not handle workloads with highly variable resource demands efficiently, as the fixed time slice may not align with the computational needs of all tasks.
- Performance can be inconsistent because different workloads may have varying computational and memory requirements, leading to potential resource contention.
- Users have limited control over the exact amount of GPU resources allocated to each workload, making it difficult to guarantee performance for specific tasks.
How does GPU Time-Slicing work?
As mentioned above, the GPU Time-Slicing allocates the GPU resources to different processes for each time slice, based on the defined profiles. Here are the major steps involved in scheduling and executing GPU tasks using Time-Slicing.
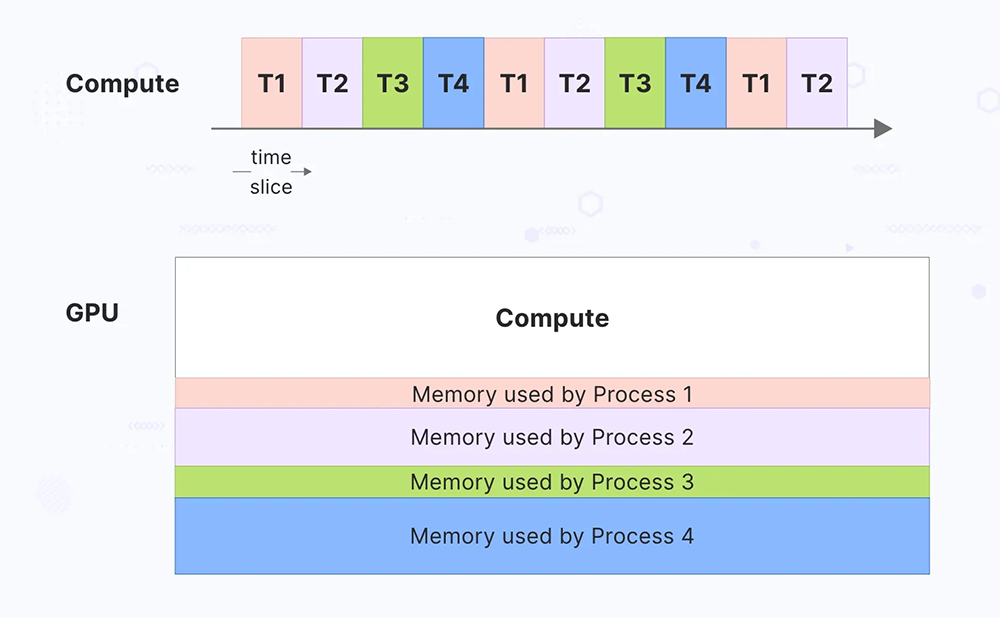
Scheduler implementation
A GPU scheduler manages the allocation of GPU resources among different tasks. It slices the GPU’s time into intervals and assigns these time slots to various workloads or VMs based on predefined policies. Each time slice represents a fixed duration during which a specific workload has exclusive access to the GPU resources. These slices are typically short, allowing the GPU to switch between tasks rapidly.
Task queuing
Incoming GPU tasks are placed in a queue managed by the scheduler. The scheduler organizes these tasks based on priority, resource requirements, and other policies. The scheduler can use different strategies, such as round-robin.
Resource allocation
When a time slice allocated to a task ends, the GPU performs a context switch to save the state of the current task and load the state of the next task. This involves saving and restoring registers, memory pointers, and other relevant data. The GPU ensures that each task gets access to the necessary compute and memory resources during its allocated time slice. This includes managing memory allocations and ensuring that data is correctly transferred to and from the GPU.
Execution and monitoring
During its allocated time slice, the task runs on the GPU, utilizing the compute cores, memory, and other resources. The scheduler monitors the performance of each task, adjusting time slices and resource allocation as needed to optimize overall GPU utilization and ensure fair access.
Hardware requirements
There is no specific hardware requirement for GPU Time-Slicing. Most modern GPUs support it.
vGPU vs MIG vs GPU Timeslicing
Here’s a comparison of the three GPU partitioning technologies at a bird’s eye view. This chart provides a quick reference to their differences in different features such as partition type, SM/memory quality of service, error isolation,etc.
| Features | vGPU | Time Slicing | MIG |
|---|---|---|---|
| Partition Type | Logical | Logical | Physical |
| Max Partitions | Upto 20 (with VCS & A100 80GB GPU) | Unlimited | 7 |
| SM QOS | ❌ | ❌ | ✅ |
| Memory QoS | ❌ | ❌ | ✅ |
| Error Isolation | ✅ | ❌ | ✅ |
| Reconfigure | Dynamic | Dynamic | Requires Reboot |
| GPU Support | Most GPU | Most GPU | A100, A30, Blackwell & Hopper Series |
Summary
In this blog post, we explored three GPU virtualization technologies: vGPU, Multi-Instance GPU (MIG), and GPU Time-Slicing.
- vGPU (Virtual GPU): Allows a single physical GPU to be shared among multiple virtual machines (VMs), each with its own dedicated portion of the GPU’s resources.
- Multi-Instance GPU (MIG): Partitions a single physical GPU into multiple isolated instances, each with dedicated compute, memory, and bandwidth resources at the hardware level.
- GPU Time-Slicing: Divides the GPU’s processing time into discrete intervals, allowing multiple tasks to share the GPU in a time-multiplexed manner.
Now that you have learned the difference between vGPU, GPU Time-slicing and MIG, we’d be happy to hear on how you are tinkering with these technologies. Want to go production level and need support, you can bring in AI & GPU Cloud experts to help you build your own AI cloud.
If you found this post useful and informative, subscribe to our weekly newsletter for more posts like this. Do start a conversation about this post on LinkedIn. I’d love to hear your thoughts.
Stay updated with latest in AI and Cloud Native tech
We hate 😖 spam as much as you do! You're in a safe company.
Only delivering solid AI & cloud native content.
Posts You Might Like