
Mastering Workload Specifications: Finding the Right Fit for Your Developers
 Mathieu Benoit
Mathieu Benoit  Atulpriya Sharma
Atulpriya Sharma Despite the initial excitement surrounding containers as a solution to the “it runs on my machine” problem, development teams encountered hurdles in realizing this promise. Packaging applications into containers and deploying them across different environments turned out to be quite complex, especially at scale. Many teams find themselves navigating a maze of tools for scripting, templating, and managing environment - and platform-specific configuration to get their apps running consistently.
Today, cloud-native development teams commonly refer to their containerized applications as “workloads” - a term that encapsulates the additional complexity and configuration required to run a container. Simply put, a workload is a specification of how a container should be run, whether it’s a cron job or a microservice, for example. This brings the community back to the question: How can we ensure the portability of workloads across diverse deployment environments?
The problem? Cognitive load & configuration inconsistencies
To understand why development teams encounter bottlenecks when promoting their workloads from local development to remote production environments, let’s look at a typical developer workflow. Locally, developers often rely on lightweight tools like Docker Compose to test and run a workload. When transitioning to remote environments, however, a new host of tooling, such as Helm, Terraform, or Argo CD is introduced - a glance at the CNCF tooling landscape underlines the variety of tech and tools developers potentially face.
Each platform and tool comes with its own set of configuration rules, making it difficult to keep their workload’s configuration in sync across environments. How can developers ensure that the configuration in Helm aligns with what was specified in Docker Compose, and vice versa? How do they provision dependencies, like databases, accurately via Terraform?
The specialized knowledge and operational expertise required for production environments increases the risk of wrongly specified or inconsistent configuration. Teams adopt different strategies to address these challenges, from seeking assistance from experienced engineers to maintaining documentation or using ticketing systems.
Workload specifications were developed in response to these challenges. They offer a standardized approach to configuring workloads across environments, aiming to reduce the cognitive burden on developers and ensure consistent configuration regardless of the deployment platform.
Workload specification 101: Introducing Score
To understand the concepts and benefits of workload specifications, we’ll dive into the Score spec, an open-source project that was launched in 2022. Using Score as our example, we’ll demonstrate how workload specifications look and behave, providing a more detailed understanding of their functionality and use cases.
Score is a container-based and platform-agnostic workload specification that sits alongside the developer’s workload in source-control and is characterized by the following features:
-
Tightly scoped: Score simplifies workload definition by focusing on common entities, effectively shielding developers from the configurational complexity of container orchestration tech and tooling. For example, specifying a dependency is as easy as saying, “My workload relies on a PostgreSQL database”.
-
Declarative: Developers define their requirements declaratively, leaving the implementation details—such as provisioning databases or managing secrets—to the underlying platform.
-
Platform agnostic: Score is compatible with various container orchestration tools, including Google Cloud Run, Helm, or Kustomize, making it adaptable across different tech stacks.
Below is an example Score spec describing a workload with an image, container overrides, and dependencies on the PostgreSQL database and another service:
apiVersion: score.dev/v1b1
metadata:
name: service-a
containers:
service-a:
image: busybox
command: ["/bin/sh"]
args: ["-c", "while true; do echo service-a: Hello $${FRIEND}! Connecting to $${CONNECTION_STRING}...; sleep 10; done"]
variables:
FRIEND: ${resources.env.NAME}
CONNECTION_STRING: postgresql://${resources.db.user}:${resources.db.password}@${resources.db.host}:${resources.db.port}/${resources.db.name}
resources:
env:
type: environment
db:
type: postgres
service-b:
type: service
The counterpart of the Score spec is a Score implementation, a CLI that the Score file can be executed against to generate a platform-specific configuration file. As shown in the diagram below, the same Score file can be executed against various platform CLIs:
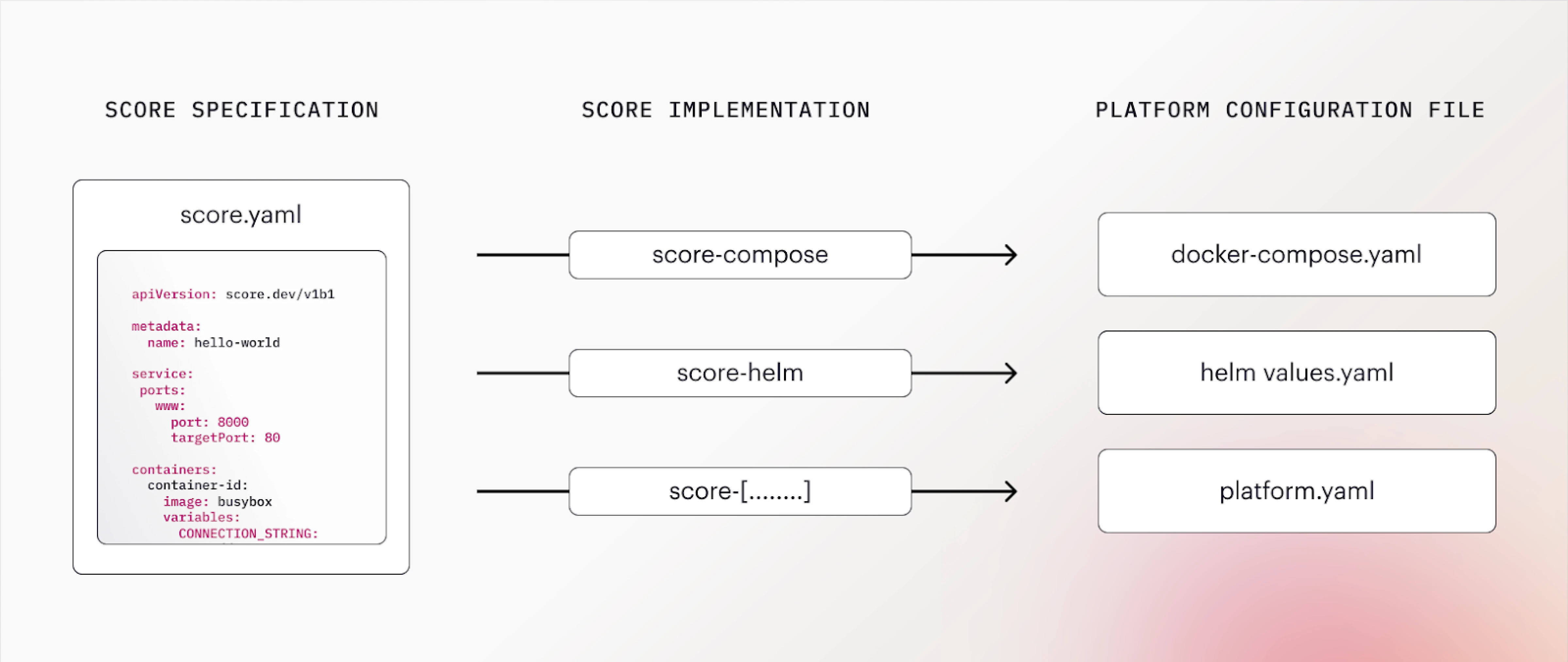
The Score spec allows you to establish a single source of truth for your workload’s configuration, from which configuration for different target platforms and environments can be generated in a one directional manner. Next to reducing cognitive load for developers, this minimizes the risk of configuration inconsistencies between environments. With Score, the same workload can now be run on completely different technology stacks without the developer needing to be an expert in any of them.
Choosing the right tool by putting developers first
When evaluating whether a workload specification fits your needs and assessing how it could fit into your workflow, there are a series of tool-specific criteria you might want to orient towards. This likely includes items such as compatibility with existing infrastructure, platform-agnosticism (to avoid vendor lock-in), or a low learning curve. However, focusing solely on tool-related requirements has its limitations.
Embedding a workload specification within your internal developer platform (IDP) offers an opportunity to treat your developers and the broader engineering team as customers. Ensuring that the workload specification and its implementation are driven by real use cases and address pain points experienced by your developers is important for the success of your IDP.
Tooling radar: options to explore
When exploring the landscape of tooling that prioritizes developer experience and offers a specification file for developers to describe their workloads or applications, you’ll encounter a range of options with different use cases and scopes. Here are a few examples:
-
Score: The Score spec is an open-source workload specification. It is platform-agnostic and compute-agnostic, with the only limitation being the use of OCI containers. Through Score implementation CLIs, it can be translated into various platform-specific files. Score solely describes the workload and assumes that users already have a platform in place for rendering, orchestrating, and managing their applications.
-
OAM: OAM is a platform-agnostic open-source specification that defines cloud native applications. It focuses on Kubernetes and the entire application, including multiple workloads and related configuration. Its implementation (e.g. Kubevela) is a continuous delivery tool that provides application deployment and management capabilities with a PaaS like experience.
-
Radius: Radius is an open-source cloud native application platform that serves two primary purposes: enabling developers to define cloud-native application deployments (i.e. workload specification), and assisting operators in defining and deploying infrastructure recipes (i.e. platform orchestrator). As for workload specification, Radius currently allows developers to define their applications using Bicep or Kubernetes annotations.
-
Acorn: The Acorn file allows developers to describe their workloads and its dependencies. Users need to install the Acorn runtime in their cluster to run these files. Its primary use cases include setting up demo and training environments, enabling users to easily share and launch applications.
-
Devfile: Devfile is a YAML-based specification for configuring development environments. It enables developers to define environments using components like Docker containers, specifying details such as memory limits, commands, ports, and source code mounting. By providing a standardized format for describing environments, Devfile promotes portability, collaboration, and consistency across teams.
-
Dagger: Dagger enables you to code your workflows like CI/CD pipelines in the same language as your application, making them easier and faster. It runs your pipelines as standard OCI containers. Utilizing a Dagger SDK aligned with your programming language, you can programmatically prepare workflows for execution. With this as input, the underlying Dagger engine computes a Directed Acyclic Graph of operations required to process operations.
Have insights about other workload specifications not mentioned here? We’re eager to learn more, don’t hesitate to drop us a message.
Join the discussion!
In this article, we explored the “what” and “how” of workload specifications. If you’d like to learn more about this topic, we recommend checking out the recording of the webinar ‘Deep Dive into Workload Specifications with Score.’ This session also includes a demo, offering more tangible insights into workload specifications.
We’d love to hear your thoughts and feedback on workload specifications, as well as any potential use cases you see for your team. If you’re interested in keeping the discussion going, reach out to us anytime!
This is a collaborative guest post featuring Susa and Mathieu. Susa is a maintainer of the open source project Score and works as a product manager at Humanitec. Mathieu is a customer success manager at Humanitec with experience as an engineer and solution architect.
Stay updated with latest in AI and Cloud Native tech
We hate 😖 spam as much as you do! You're in a safe company.
Only delivering solid AI & cloud native content.
Posts You Might Like









