
How to use CoreDNS Effectively with Kubernetes

Background story
We were increasing HTTP requests for one of our applications, hosted on the Kubernetes cluster, which resulted in a spike of 5xx errors. The application is a GraphQL server calling a lot of external APIs and then returning an aggregated response. Our initial response was to increase the number of replicas for the application to see if it improves the performance and reduces errors. As we drilled down further with the application developer, found most of the failures were related to DNS resolution. That’s where we started drilling down DNS resolution in Kubernetes.
This post highlights our learnings related to using CoreDNS effectively with Kubernetes, as we did deep dive in process of configuring and troubleshooting.
CoreDNS Metrics
DNS server stores record in its database and answers domain name query using the database. If the DNS server doesn’t have this data, it tries to find for a solution from other DNS servers.
What is CoreDNS in Kubernetes?
CoreDNS is an open source, flexible, extensible DNS server that can be used as Kubernetes cluster DNS. CoreDNS became the default DNS service for Kubernetes 1.13+ onwards. Nowadays, when you are using a managed Kubernetes cluster or you are self-managing a cluster for your application workloads, you often focus on tweaking your application but not much on the services provided by Kubernetes or how you are leveraging them. DNS resolution is the basic requirement of any application so you need to ensure it’s working properly. We would suggest looking at dns-debugging-resolution troubleshooting guide and ensure your CoreDNS is configured and running properly.
By default, when you provision a cluster you should always have a dashboard to observe for key CoreDNS metrics. For getting CoreDNS metrics you should have Prometheus plugin enabled as part of the CoreDNS config.
Below sample config using prometheus plugin to enable metrics collection from CoreDNS instance.
.:53 {
errors
health
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods verified
fallthrough in-addr.arpa ip6.arpa
}
prometheus :9153
forward . /etc/resolv.conf
cache 30
loop
reload
loadbalance
}
Following are the key coreDNS metrics, we would suggest to have in your dashboard: If you are using Prometheus, DataDog, Kibana etc, you may find ready to use dashboard template from community/provider.
- Cache Hit percentage: Percentage of requests responded using CoreDNS cache
- DNS requests latency
- CoreDNS: Time taken by CoreDNS to process DNS request
- Upstream server: Time taken to process DNS request forwarded to upstream
- Number of requests forwarded to upstream servers
- Error codes for requests
- NXDomain: Non-Existent Domain
- FormErr: Format Error in DNS request
- ServFail: Server Failure
- NoError: No Error, successfully processed request
- CoreDNS resource usage: Different resources consumed by server such as memory, CPU etc.
We were using DataDog for specific application monitoring. Following is just a sample dashboard I built with DataDog for my analysis.
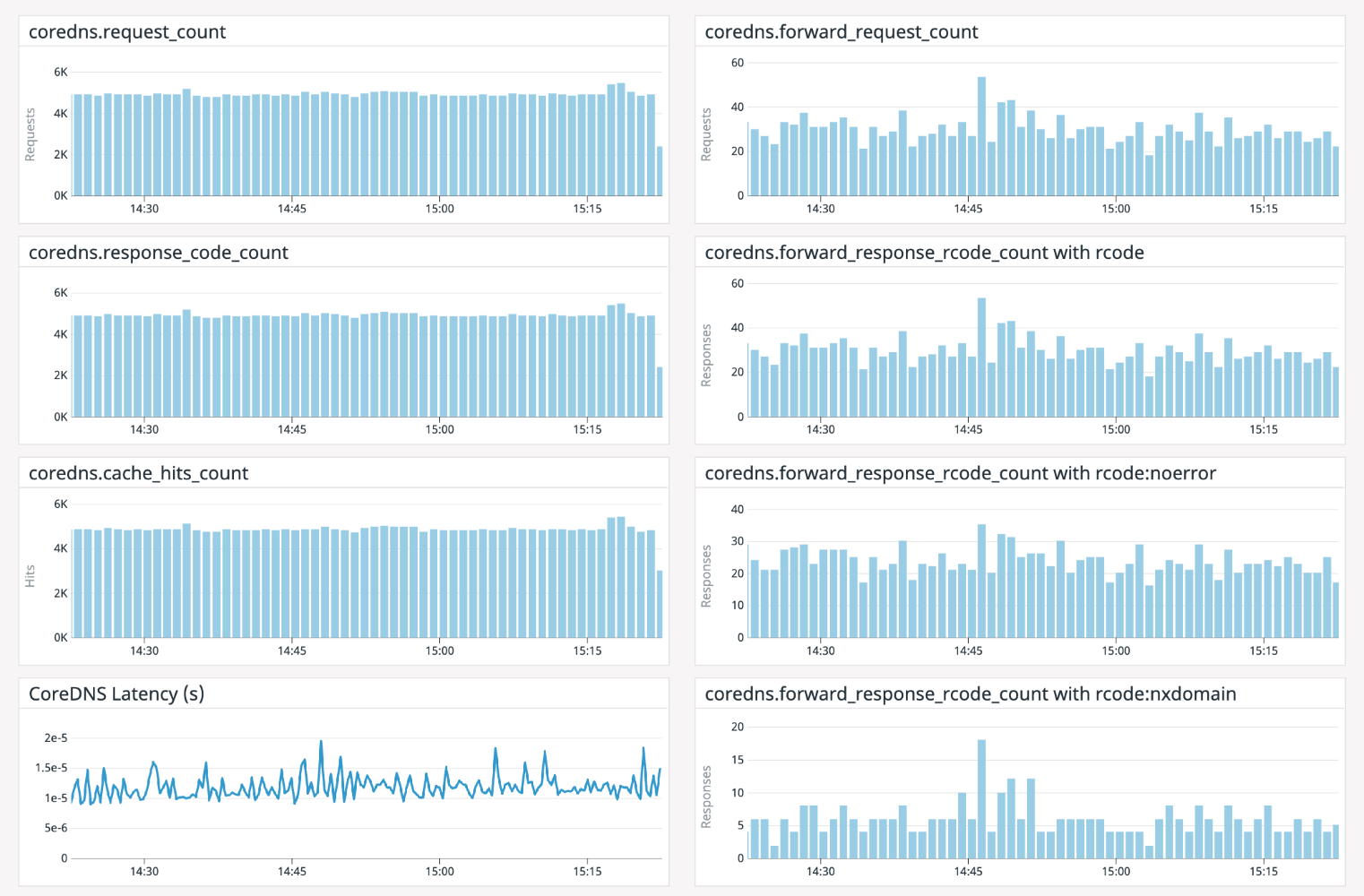
How to reduce CoreDNS errors?
As we started drilling down more into how the application is making requests to CoreDNS, we observed most of the outbound requests happening through the application to an external API server.
This is typically how resolv.conf looks in the application deployment pod.
nameserver 10.100.0.10
search kube-namespace.svc.cluster.local svc.cluster.local cluster.local us-west-2.compute.internal
options ndots:5
If you understand how Kubernetes tries to resolve an FQDN, it tries to DNS lookup at different levels.
Considering the above DNS config, when the DNS resolver sends a query to the CoreDNS server, it tries to search the domain considering the search path.
If we are looking for a domain boktube.io, it would make the following queries and it receives a successful response in the last query.
botkube.io.kube-namespace.svc.cluster.local <= NXDomain
botkube.io.svc.cluster.local <= NXDomain
boktube.io.cluster.local <= NXDomain
botkube.io.us-west-2.compute.internal <= NXDomain
botkube.io <= NoERROR
As we were making too many external lookups, we were getting a lot of NXDomain responses for DNS searches. To optimize this we customized spec.template.spec.dnsConfig in the Deployment object. This is how change looks like:
dnsPolicy: ClusterFirst
dnsConfig:
options:
- name: ndots
value: "1"
With the above change, resolve.conf on pods changed. The search was being performed only for an external domain. This reduced number of queries to DNS servers. This also helped in reducing 5xx errors for an application. You can notice the difference in the NXDomain response count in the following graph.
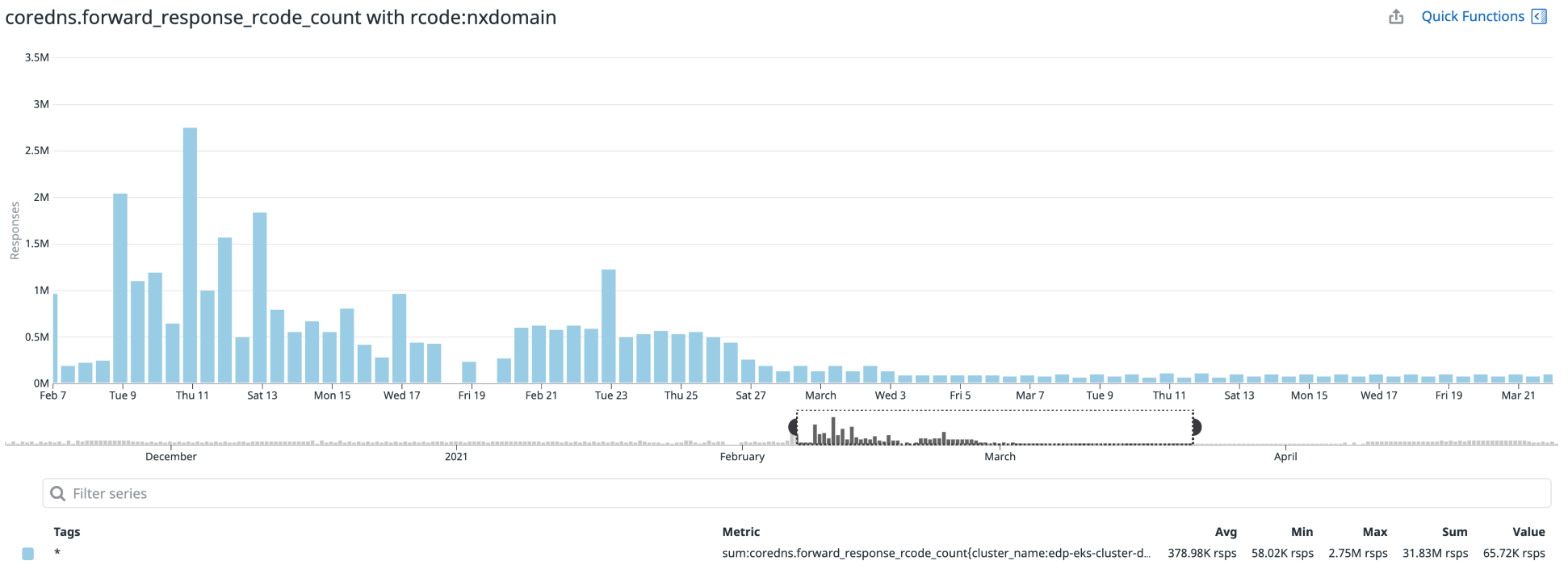
A better solution for this problem is Node Level Cache which is introduced Kubernetes 1.18+.
How to customize CoreDNS to your needs?
We can customize CoreDNS by using plugins. Kubernetes supports a different kind of workload and the standard CoreDNS config may not fit all your needs. CoreDNS has a couple of in-tree and external plugins. Depending on the kind of workloads you are running on your cluster, let’s say applications intercommunicating with each other or standalone apps that are interacting outside your Kubernetes cluster, the kind of FQDN you are trying to resolve might vary. We should try to adjust the knobs of CoreDNS accordingly. Suppose you are running Kubernetes in a particular public/private cloud and most of the DNS backed applications are in the same cloud. In that case, CoreDNS also provides particular cloud-related or generic plugins which can be used to extend DNS zone records.
If you are interested in customizing DNS behaviour for your needs, we would suggest going through the book “Learning CoreDNS” by Cricket Liu and John Belamaric. Book provides a detailed overview of different CoreDNS plugins with their use cases. It also covers CoreDNS + Kubernetes integration in depth.
If you are running an appropriate number of instances of CoreDNS in your Kubernetes cluster or not is one of the critical factors to decide. It’s recommended to run a least two instances of the CoreDNS servers for a better guarantee of DNS requests being served. Depending upon the number of requests being served, nature of requests, number of workloads running on the cluster, and size of cluster you may need to add extra instances of CoreDNS or configure HPA (Horizontal Pod Autoscaler) for your cluster. Factors like the number of requests being served, nature of requests, number of workloads running on the cluster and cluster size should help you in deciding the number of CoreDNS instances. You may need to add extra instances of CoreDNS or configure HPA (Horizontal Pod Autoscaler) for your cluster.
Summary
This blog post tries to highlight the importance of the DNS request cycle in Kubernetes, and many times you would end up in a situation where you start with “it’s not DNS” but end up “it’s always DNS !”. So be careful of these landmines.
Enjoyed the article? Let’s start a conversation on Twitter and share your “It’s always DNS” stories and how it was resolved.
Looking for help with building your DevOps strategy or want to outsource DevOps to the experts? learn why so many startups & enterprises consider us as one of the best DevOps consulting & services companies.
Stay updated with latest in AI and Cloud Native tech
We hate 😖 spam as much as you do! You're in a safe company.
Only delivering solid AI & cloud native content.
Posts You Might Like






