What are Vector Databases? A Beginner's Guide

Have you ever used AI tools like ChatGPT to chat with a robot or Stable Diffusion to generate unique images? Wondered how they work?
Familiar apps, like the contacts app you use, use structured data, i.e., name, phone number, email address, and a few more text and numeric fields. While AI apps deal with different kinds of data that are unstructured. Some examples of unstructured data are articles, chats, pictures, multimedia, etc. These are quite complex for computer programs to process and understand the context.
Applications like contact apps work very well with SQL-type databases since their requirements are fairly simple. However, when it comes to AI apps and tools that refer to different kinds of unstructured data, regular databases aren’t made to handle it. This is where vector databases come in! They’re a special kind of database that helps AI platforms store and process unstructured data easily. That is why many AI tools are switching to vector databases or using them from the beginning.

Vector databases are the backbone of any AI application. In this blog post, we’ll understand what they are and how they are different from traditional SQL and No-SQL databases, along with understanding the benefits they bring to the table. Let’s get started 🚀.
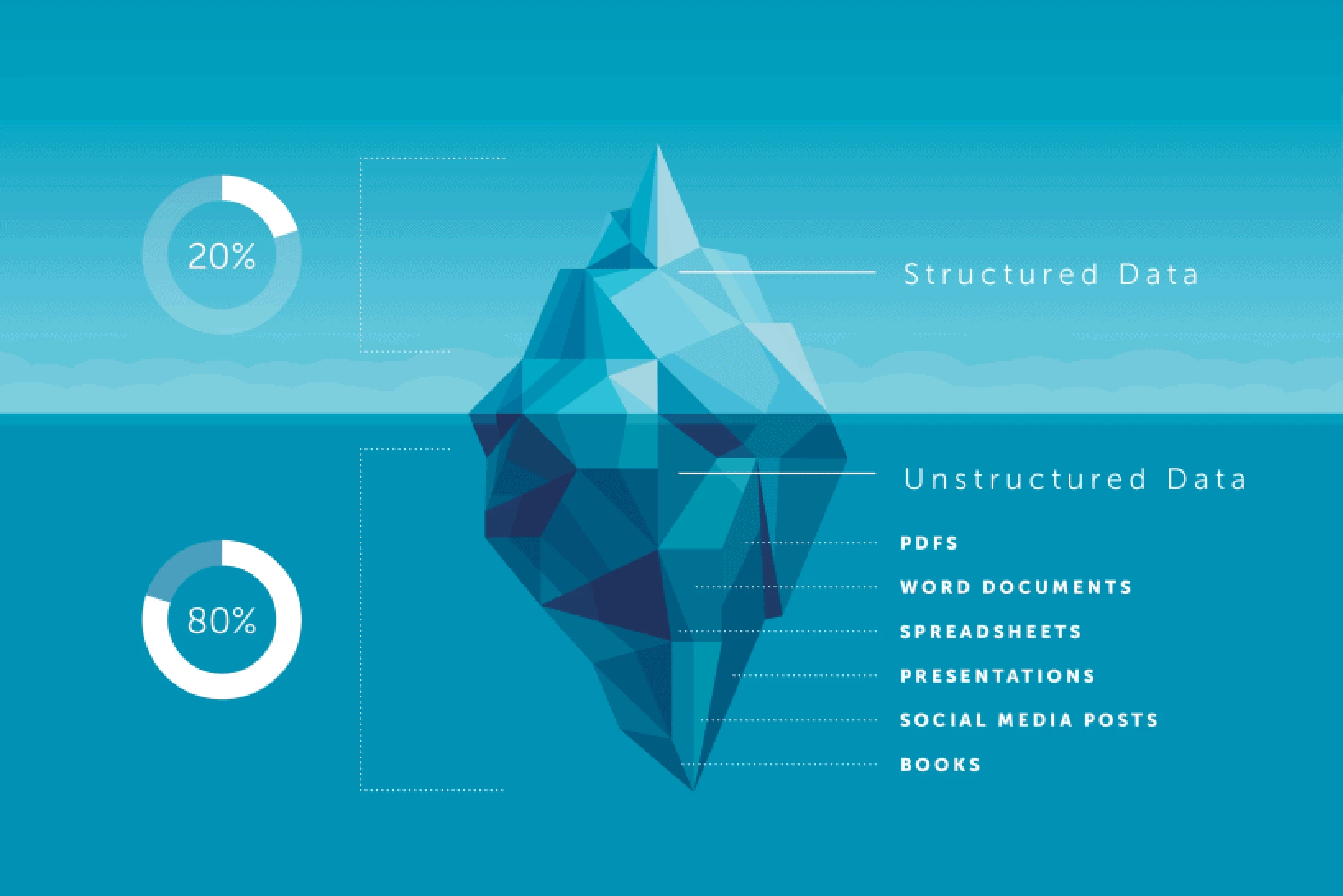
Types of data
Before diving deeper into the vectors and vector databases, let’s first understand the types of data and how they affect the type of database best suited for its storage and querying capabilities.
Structured data
Any data that has a predefined and fixed schema for it is called structured data. This data can be represented in a tabular format. SQL databases, spreadsheets, etc. are best suited for storing and interacting with this type of data.
Semi-structured data
Semi-structured data is data with a flexible schema. In other words, it is “self-describing” data such as JSON or XML files. These files contain data as well as structural details about themselves. This type of data is ever-evolving, as it lacks a fixed schema.
Document stores, Key-Value stores, and Graph databases are some examples of suitable databases for storing and analyzing semi-structured data.
Unstructured data
Unstructured data is any other data that is mostly in the form of natural language and/or in multimedia format. Some examples of this type of data would be news articles, social media discussions, images, audio-visuals, etc. This is the largest form in which the data exists today and is the most difficult data to comprehend for computer systems as well. For example, consider a simple sentence “Sam likes Football”. Depending on the context and the background of the person, “Football” can either mean American Football or Soccer. Similarly, a single picture can be seen and interpreted in numerous ways depending on the person, their point of view as well as the required information being seeked out of it. This is called latent semantic meaning of the given data.
The latent semantic meaning of the data can be extracted by evaluating it against a large number of attributes, such as words immediately preceding and following the text, context of the data, person’s background, grammar, etc., and converting it into n-dimensional numerical arrays, i.e., vector embeddings.
Vector databases excel at storing, indexing, and querying such data.
Below image represents how the same kind of data can be represented in three different types listed above.

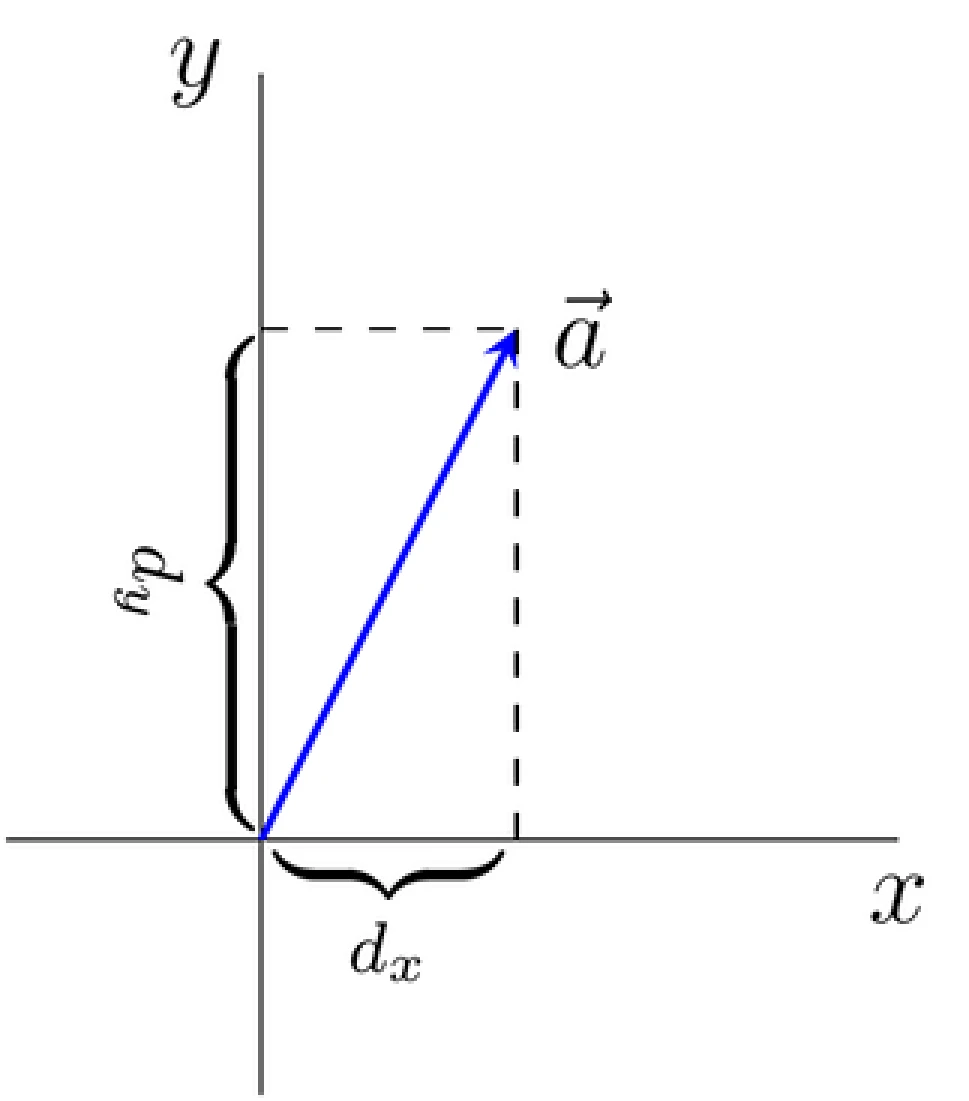
What are vectors?
Vector is a mathematical concept which indicates information in more than one dimension. Being able to represent data in multiple dimensions is the key that helps vectors in AI and machine learning (ML). Unstructured data contains latent semantic meaning in multiple attributes. Hence the semantic meaning for any given data point needs to be captured with respect to all the relevant attributes for the model.
Below are some examples of unstructured data containing semantic meaning in multiple attributes.
-
Text: The text you read can contain semantic information in many ways, such as individual words, their relationships, part of speech, sentence structure, grammar rules, overall topic/theme, sentiment, etc. Depending on the purpose, multiple AI models can use the same text data to evaluate the latent semantic meaning and form different vector data.
-
Images: Pixel data in images can be used to describe the image in vector forms. Some of the features that the models can consider would be colors, tones, shapes, edges, brightness, identifying objects, location, arrangement, artistic style, etc.
-
Audio: For audio data, sound waves can be converted to numerical representations and evaluated on a number of parameters such as volume, timbre, tempo, attack and decay, frequencies, harmonics, etc.
Vector embeddings
In simple terms, vector embeddings, a.k.a. embeddings are high-dimensional vectors generated by neural networks. A typical vector database stores many such embeddings.
Vectors help us represent data in mathematical form since modern CPUs and GPUs are best suited for working with mathematical data. Though, just turning data into a mathematical form isn’t useful if it cannot represent the meaning of the data it represents. For example, we can easily compare words in two sentences using computers, but that may not tell us whether they mean the same thing or if they are about the same topic. This is where vector embeddings and embedding models come into play. The embedding model takes a large amount of labeled data and converts it into numerical representation in a high-dimensional space. Each dimension represents a specific attribute or feature of the data extracted from it.
Here is an example of vector embeddings generated using word2vec, a well-known model used to generate word embeddings. As you can see, it converts given words into an array of floating point numbers. It does that by evaluating the words on a set number of parameters, since computers can easily understand and process numbers than the meaning of words themselves.
Word: “king”
Embedding: [-0.25, 0.42, 0.18, …, 0.71] (This is a reduced dimensionality example, actual embeddings can have hundreds of dimensions)
Word: “queen”
Embedding: [-0.31, 0.38, 0.24, …, 0.68]
Word: “computer”
Embedding: [0.17, -0.52, 0.89, …, 0.34]
Word2vec is a classic example of a text embedding model for Natural Language Processing (NLP) algorithms. This model encodes semantic meaning and relationships between words. Thus, it is able to represent words with similar meanings closer together. The below image shows the visualization produced by TensorFlow’s projector tool for this model.
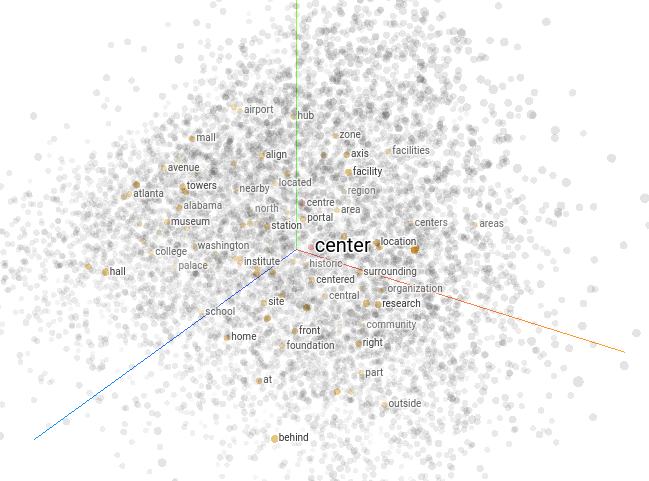
(Word2vec 10k embedding projector)
How do vector databases work?
Vector databases help store the vector embeddings generated by the embedding model. These vector embeddings are multidimensional numerical arrays that can sometimes span across hundreds of dimensions. Traditional scalar based databases can’t work with this type of data efficiently; this is why we need specialized databases like vector databases which are specifically designed to handle this data type. Some reasons why traditional databases can’t work with vector data efficiently are:
- Vector embeddings that are high-dimensional arrays of numbers don’t fit neatly into a structured format.
- The indexing algorithms of traditional databases are optimized for structured and semi-structured data. Vector embeddings need a different set of algorithms for indexing.
- Traditional databases lack the functionality to perform complex distance calculations, like cosine similarity, needed to compare and query vectors.
Below diagram shows a simplified way a typical vector database works.
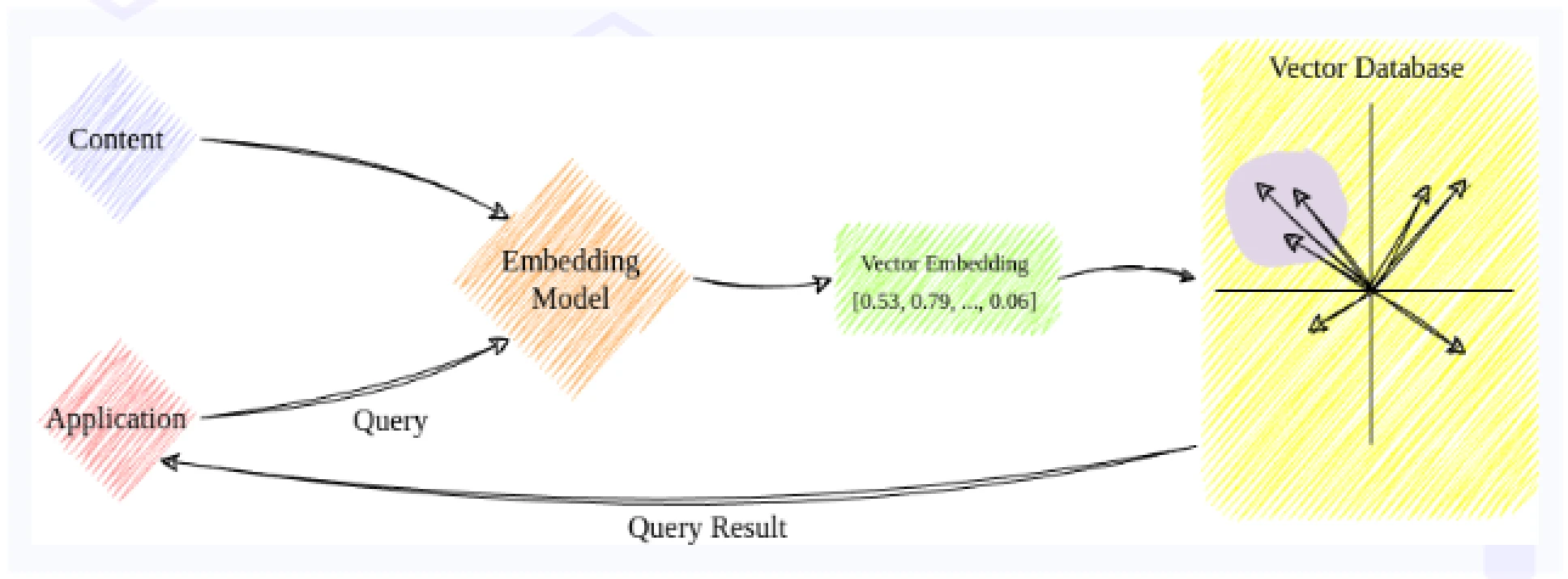
First, we feed the embedding model with the required labeled data in large quantities. The embedding model consists of execution of a data pipeline that largely consists of two steps:
-
Preprocessing: During preprocessing, the model cleans the data, removes noise, and inconsistencies, and then normalizes the data.
-
Embedding: The embedding stage includes feature extraction & vectorization (encoding) of the data followed by dimensionality reduction. The last step reduces the number of dimensions of the vector, if needed, for efficiency.
The vector embeddings are then inserted into the vector database for long term storage. The embeddings also contain some reference to the original content it was created from. Once enough vector data has been inserted into the database, the data that has similar semantic meaning naturally gravitates closer together.
In order to get query results from the database, the query is also run through the same embedding model as the data. This converts the query into another vector. The vector database then searches for data points closest to the query vector based on the distance metric and returns the results. In some cases, the database also needs to post-process the nearest neighbors of the queried data before returning them.
Indexing algorithms
The AI and ML applications need to be trained on a large amount of data. In addition to that, the fact that the vector embeddings generated can have hundreds of dimensions means that the vector databases need to store a huge amount of data. Querying over such a huge amount of data is quite cumbersome, even for vector databases. Hence, similar to scalar based databases, indexing also helps vector databases with faster query retrievals. The vector db indexes create a quickly traversable data structure using several algorithms. Below are some of the common ones.
Hierarchical Navigable Small World (HNSW)
HNSW builds a hierarchical structure. Each node in the hierarchy represents a set of vectors, and each edge represents the similarity between the vectors. It organizes the data points into a series of graphs at different levels, and similar data points are connected within each graph.
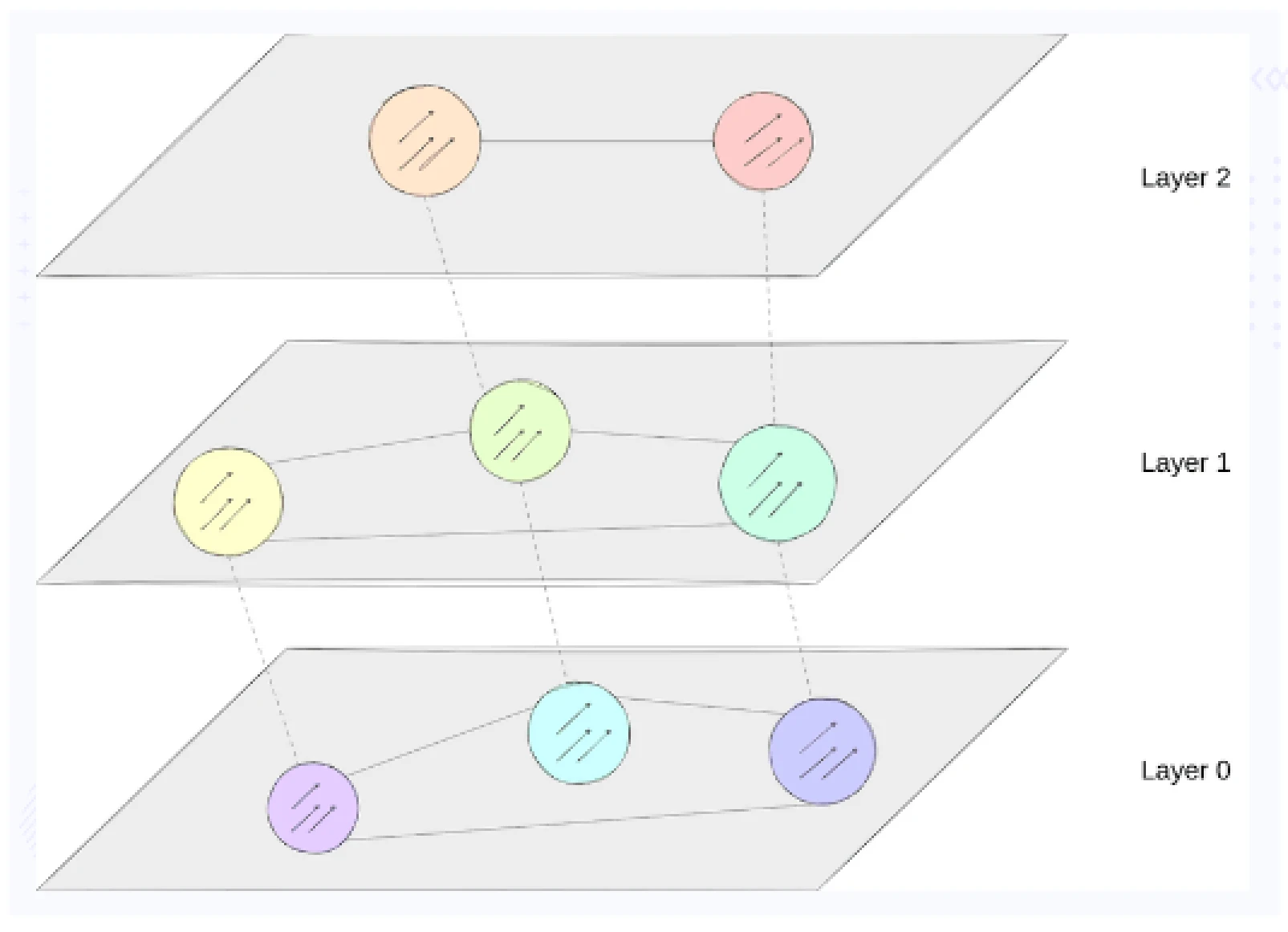
The benefits of HNSW include efficient approximate nearest neighbor searches, fast search times, and scalability with large datasets.
Locality Sensitive Hashing (LSH)
Locality sensitive hashing projects data points onto multiple hash tables using hash functions. These hash functions map similar vectors to the same or similar bucket which helps the database locating the query results faster.
The benefits of using LSH for indexing are very fast filtering of dissimilar points and being especially useful for large datasets with high dimensionality.
Product Quantization (PQ)
Product quantization is a lossy compression technique for high dimensional data. It reduces the dimensionality of the vectors into subvectors using codebooks and quantizes each subvector separately. During encoding, the original vector is compared to the codewords in the codebook, and the closest ones are selected to represent the original vector.
PQ helps in efficient approximate nearest neighbor search and reduction in storage requirements.
Use cases of Vector databases
Vector databases are a useful tool in many applications. Here are some use cases of the same.
Recommendation systems
Recommending articles, movies, music, products, etc., based on user preferences and/or the given description in text or other formats. They can store user profiles and item embeddings for efficient retrieval of similar items to recommend. This can help social media platforms, media publishing houses, and OTT platforms engage users and build brand loyalty.
Natural language processing (NLP)
Vector databases make tasks like sentiment analysis, topic modeling, and machine translation possible and efficient. They can store word as well as sentence embeddings enabling fast processing of large natural language data. This helps search engines provide better results, as well as chatbots and virtual assistants.
Fraud detection and anomaly detection
Vector databases help in analyzing and detecting unusual patterns, objects, behaviors in various data forms. They can store historical transaction embeddings or sensor data embeddings, which allows real-time detection of suspicious patterns. It is used by financial organizations to prevent financial frauds in their tracks.
Drug discovery and material science
Finding similarity to existing data is an important capability for identifying potential drug candidates or new alternatives to existing materials. Vector databases can store molecular embeddings or material property embeddings, enabling faster scientific discoveries. This helps to significantly reduce the time it takes to develop new drugs and discover newer materials for specific applications.
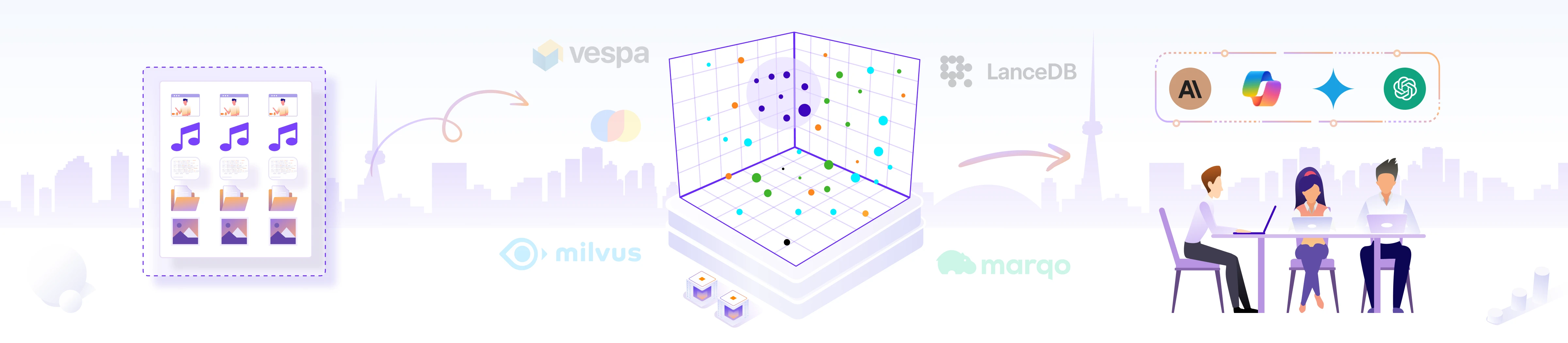
Vector DB classification
The vector databases are broadly classified using two aspects.
- Dedicated vector database
- Licensing model
Dedicated vector databases have certain advantages over traditional databases that support vector search. They are built for speed, with optimized indexing and scalability. On the other hand, traditional databases with support for vector search have advantages like the ability to handle structured and/or unstructured data along with vectors, with a smoother learning curve.

The diagram above shows a few of the popular vector database options available today and how they fit into the landscape.
Conclusion
Vector databases are revolutionizing how we handle and interact with large and complex data in the age of artificial intelligence. They unlock a vast range of possibilities through their ability to capture, persist and efficiently search through the essence of data. From powering recommendation systems to accelerating scientific discovery, vector databases are bound to play a central role in the upcoming data driven future.
As new vector databases emerge and evolve, we can expect even faster speeds, larger storage capacities, more sophisticated indexing and world-wide adoption of them across industries.
Now that you have learned about vector databases, how they work, their use cases, and classification, you can bring in AI & GPU Cloud experts to help you build your own AI cloud.
If you found this post useful and informative, subscribe to our weekly newsletter for more posts like this. Do start a conversation about this post on LinkedIn. I’d love to hear your thoughts.
Stay updated with latest in AI and Cloud Native tech
We hate 😖 spam as much as you do! You're in a safe company.
Only delivering solid AI & cloud native content.
Posts You Might Like








{kind=link}