Cloud Native Transformation for a SaaS Company

Client Details
The customer has been building products and solutions in the travel space focused on hotel, flight bookings and loyalty cards for corporate customers worldwide. The products are offered as SaaS to end customers and need to comply with standards such as PCI etc.
Key Challenges
AWS ECS, On premises and cloud lock in The customer had been running their workloads on AWS ECS as Docker containers. While this had served them well so far it was limiting their ability to expand to other cloud providers in a consistent manner. Also some deployments which were on-premises were very different than the one on AWS ECS, which lead to operational overhead and different ways to manage different deployment units. The customer wanted one consistent way no matter if the deployment was in AWS, Azure or on-premises.
Security and software supply chain Many components were running a pretty old version of runtime or libraries etc. Due to disparity in environments across AWS ECS and on-premises infrastructure - it was not easy to upgrade fast enough and frequently enough. Also security posture in the current setup was not fully developed so the cloud native transformation was a good opportunity to scale and develop the security posture.
Custom developed monitoring & alerting stack The customer had over time developed a well functional monitoring and tracing stack which was developed in-house. While this worked well, the cost of maintaining it was not worth it considering the open source alternatives. The customer was seeking guidance and support in choosing the best breed of open source technologies and implementing that so the in-house stack can be decommissioned and use industry best practices from open source software.
Scope of Work
Assessment
InfraCloud started with a two week onsite assessment of existing technology stack, deployment and application architecture and working with team members and stakeholders to understand the objectives and goals. The assessment phase presented a report with recommendations of architecture and a plan for transformation.
Phased Implementation
InfraCloud divided the implementation in phases taking into account the educating and coaching the teams while onboarding 40+ business applications on the new platform.
Phase 1: Design, pilot applications and tiger teams
Tiger team & Coaching The first phase was focused on getting a tiger team setup so that they can start making early progress in the context of the customer’s needs and build a platform. The team composition was a mix of architects and senior engineers from both the companies - this ensured that the customer’s teams also learned and started understanding the technology with a bottom up hands on approach. The teams from both sides were pairing on most tasks so that as much as the platform was getting built, the why and how was also answered by learning the technology.
| Team Member Role | InfraCloud | Customer |
|---|---|---|
| Sr. Architect | 01 | 01 |
| Sr. Cloud Native Engineers | 03 | 02 |
Design and contextualizing the technology
When adopting a new technology it is very crucial to understand the business context in which it is applied. There are no silver bullets and trying to fit one solution to all problems can lead to technical debt and rigid architecture choices which cost time and money in future.
One such decision was choosing the right monitoring system. The customer’s team was deeply familiar and comfortable with CloudWatch as a monitoring system. They were not sure if moving to something like Prometheus was absolutely necessary. The fact that their entire homegrown chatops and alerting system was built to integrate with CloudWatch complicated the decision even further.
The Architect from InfraCloud’s team engaged with customer’s teams that used CloudWatch and the ChatOps and Alerting system. There was an analysis done in terms of cost of switching to a new system, cost of using CloudWatch vs. something like Prometheus and other aspects such as long term goals of organizations. For the cost part of analysis, the InfraCloud team also published a blog which was helpful in arriving at a decision. Eventually, Prometheus was chosen as the system and quite a few parts of the homegrown ChatOps system were decided to be replaced by Alertmanager.
Pilot applications For the initial batch of applications, a medium-sized and medium complexity application was chosen to be transformed to cloud native. The patterns emerging from this migration would in turn be helpful to choose the next batch of applications to be transformed. At end of phase one following goals were achieved:
-
A working application with 6 containers and a managed DB which was tested for performance and scalability.
-
Cluster provisioning & management automation.
-
Basic cluster components such as Prometheus for monitoring, ELK stack for log management, NGINX Ingress controller as API Gateway etc. baked in the cluster.
-
This application was taken to pre-prod environments and passed all functional as well as non functional requirements.
-
At the end of phase one there was one cluster humming with one application in a production environment serving production traffic whereas the rest of the ecosystem was still to be migrated
| Phase 1 Summary and Details | |
|---|---|
| Team | Tiger Team |
| Composition | - 3 Engineer from customer - 4 InfraCloud team members |
| Goal | Move one application to Kubernetes and operationalize it. |
| Platform Changes | - One-click Kubernetes setup - Prometheus & ELK based observability stack - NGINX based ingress controller - Setup Docker & Helm Registries |
| Aplication Changes | - Rewrite/Optimize Dockerfile - Write configurable Helm chart for application |
| Next Steps | Work with seed team to replicate this success across a 6-7 initial teams Add more capabilities to existing platforms and improve specific areas |
Phase 2: Operationalizing Kubernetes, Coaching & Rolling Out
Rolling out with more teams
Once the pilot application was running in production without any challenges, it gave confidence of the platform and a concrete application to be demoed to other teams. The tiger team identified the next wave of the applications which were good candidates for adopting Kubernetes based on discussions with business & application teams. From each of these teams, an engineer was identified who had some exposure to platform technologies such as Docker at a basic level. The tiger team was now paired with one member from 6-7 teams which formed the next wave of applications to be onboarded on the Kubernetes platform. The engineers from each of these teams were named “Seed Team”
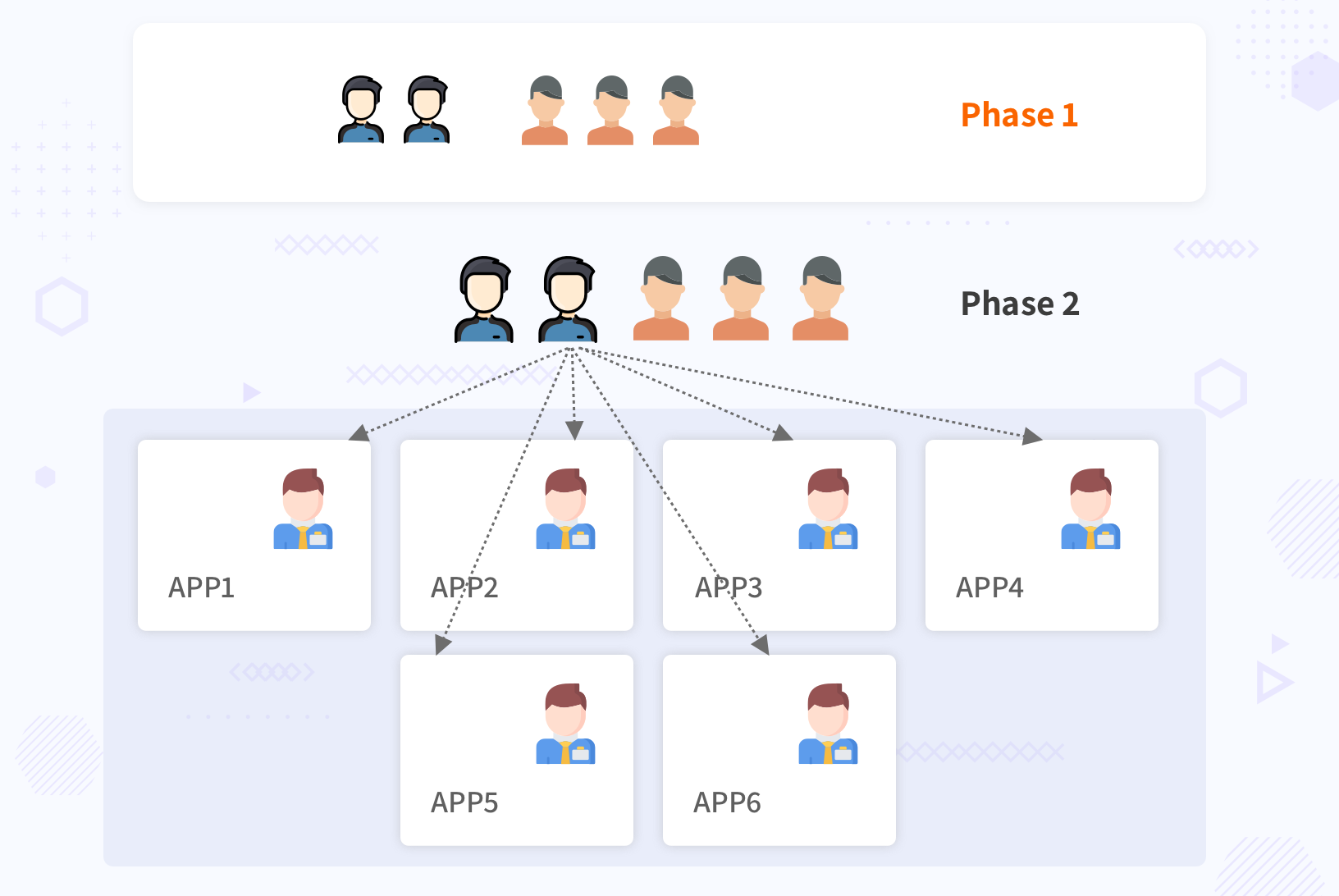
Each of engineers from the Seed Team was onboarded and trained on following areas:
- Kubernetes basics - and the details of transformation done for one application.
- Monitoring, Log management & Ingress Controller in Kubernetes.
- Let them play around in the Dev environment of pilot application to understand basics and relate to how things will change in their respective applications.
- The tiger team also did code walkthrough and demos of how they transformed their applications and what design choices they made etc.
This training helped the Seed Team to work closely with the tiger team and start helping the onboarding of their own applications to Kubernetes. The Seed Team also started doing sessions every week with broader organizations on specific technologies such as Kubernetes, Helm, Prometheus and started evangelizing the stack.
As the seed team was making changes to their applications, they ensured that if they are doing something differently than the rest of the teams (some special cases like different routing, rules, load balancer etc) it was resolved. For Example: one of the team was blocking HTTP DELETE calls on their endpoints if the IP was outside of the office IP, we added some annotations to their Ingress to achieve this.
This also ensures that the tiger team and seed team understood the application well, set the parameters like readiness, liveness probe, resource constraints etc correctly. This involved discussions with the application developers, making sure they understand how these parameters affect their application overall.
Backup, DR & High Availability As the applications started getting on-boarded - one of the key items to be tackled early on was the DR & Backup along with availability. Based on existing well understood practices and tooling a quick prototype was built with open source Velero and was put in place. There was a lot of room for improvement but at least one level of safeguard was added in case a disaster was to happen.
Playbooks for production Since the initial application was now in production, it also acted as a good way to see what kind of issues do come up and prepare playbooks for them. The Tiger team and Seed team worked closely with production teams to get involved in issues and make appropriate changes to the platform as well as writing playbooks for acting on issues.
| Phase 2 Summary and Details | ||
|---|---|---|
| Team | Tiger Team | Seed Team |
| Composition | - 3 Engineer from customer - 4 InfraCloud team members | 6 engineers from 6 application teams with basic platform knowledge |
| Goal | - Train the seed team on technologies, the changes done and templates built. - Implement basic Backup & DR. - Work with production teams to support the rolled-out applications. | - Learn about technologies and changes done by the tiger team to initial pilot application. - Contextualize changes for their application teams and start re-writing and onboarding the applications. |
| Platform Changes | - Introduce DR & Backup. - Write and help with playbooks for production issues. | NA |
| Aplication Changes | NA | - Implement changes for respective applications to be onboarded. - If any application poses a challenge- work with the tiger team to resolve those. |
| Next Steps | - Expand the seed team to help more teams onboard the applications. | - Identify the patterns & automations so that more teams can be onboarded without need to understand all underlying technologies. |
Phase 3: Future (Currently In Flight)
Patterns specific to organization The customer also embarked on a journey to find common patterns across applications and provide a simpler interface to developers. Which means when you onboard a new application, you don’t need to understand Helm or Kubenetes and all underlying details. The engineers wrote a simpler YAML file with details necessary and the pipelines were automated by the templating utility which was written by the engineers on the customer’s team with deep knowledge of various applications.
BotKube - ChatOps As initial 7-8 applications were onboarded and started using Kubernetes, it became critical for the customer to be able to enable access to Kubernetes and be aware of any critical issues. They really liked InfraCloud’s open source project BotKube. The project was used in two ways:
-
BotKube enables various teams to access Kubernetes clusters in their favourite messaging platform without losing control over the security of the platform.
-
BotKube can act as an event sink and can forward the events to a store like Elasticsearch.
The Path Ahead
At this stage in implementation, the base team and platform has been setup but there is more work to be done. The rough list of things that the customer is aiming to do in the next 6-9 months is:
-
Onboard all the applications to Kubernetes and decommission old ways of doing things.
-
Improving the Disaster recovery, backup and HA across regions - with visibility and ease of use for operations teams.
-
Decommission the in house custom written chatops platform and start using industry standard Prometheus and Alertmanager stack.
-
Long term storage for Prometheus using something like Thanos or Cortex so that metrics can be retained for longer duration without costing fortune.
-
Service Mesh implementation at some point in future.
Benefits
These are benefit that has been realized so far and more will be realized as the implementation progresses further:
-
Reduced deployment times ~20m => ~5m in most scenarios along with the ability to do rolling deployments effectively.
-
Increased parity between development and production environment.
-
A clear path to decommission the in-house custom built monitoring platform and start using a standard open source platform.
Why InfraCloud?
-
InfraCloud has helped organizations of small and mid-size to move to Kubernetes successfully. Our engineer’s experience in doing these transformations along with deep expertise in space is great for teams to kickstart their transformation.
-
Our open source projects such as BotKube and Fission fast-track your transformation without reinventing the wheel.
-
We literally live/breath/eat open source and implement the best-in-class solutions with focus on your sustainability of technology and teams beyond the transformation.
-
We don’t think there are silver bullets and approach every problem at its face value - so we ensure your teams are gradually able to learn and adopt better technologies and even more important practices and processes to better manage organizations.
Got a Question or Need Expert Advise?
Schedule a 30 mins chat with our experts to discuss more.
Trusted by 100+ companies worldwide







